[Solr] zeppelin-solrで単語の使われ方を可視化する
zeppelin-solr の事例の1つ “Text Analysis and Term Vectors” では Solr 内のドキュメントをテキスト解析してその特徴を可視化する方法の例が示されています。これを日本語のドキュメントでやってみました。
対象は日本語版Wikipediaとします。
Streaming Expressions の analyze 関数を使うと指定した文字列を形態素解析できます。
analyze("システム構成の概要", text)
「システム構成の概要」が対象の文字列、text は text フィールドで定義されている Tokenizer でトークナイズするという意味です。 Wikipedia 用のコレクションを作るときの設定で text フィールドは Kuromoji を使った形態素解析をすると定義されています。
上の analyze の実行結果は以下の通りです。
[システム, 構成, 概要]
では解析結果を使って図示してみましょう。
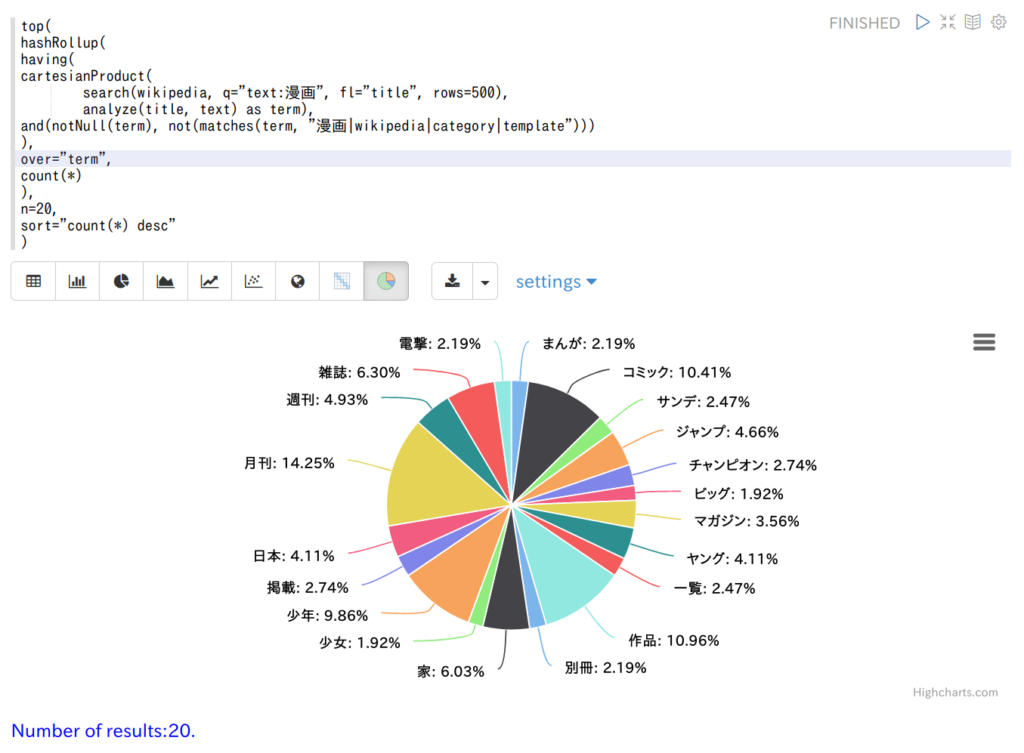
“Text Analysis and Term Vectors” では、英語のドキュメントの bi-gram をカウントして多いものトップ10をグラフにしていました。ここでは、「漫画」を含む Wikipedia の記事のタイトルを形態素解析して単語をカウントし、多いものトップ20をグラフにしました。
結果は以下の通りです。
ultimate-pie-chart を使っています。
円グラフの内訳が降順になっていないのが気になるところですが、こういう仕様のようです。