FizzBuzz のコーディング
こんにちは。開発担当のマットです。
今日の記事で、FizzBuzzという海外の子供の遊びと、プログラミングについて話をしたいと思います。
FizzBuzz とは、とても単純な子供のゲームです。 1 から数字を数え上げるゲームだけです。
1,2,3,4,5,6,7… などなど
ただし、3で割れる数を “Fizz” という
そして、5で割れる数を “Buzz” という
1,2,Fizz,4,Buzz,6,7… の感じで。
なお、3でも、5でも割れる場合、 “FizzBuzz” という
1,2,Fizz,4,Buzz,6,7,8,Fizz,Buzz,11,Fizz,13,14,FizzBuzz,16,17… などなど
基本的に、二人で遊んで、交合に数字をできるだけ早く言うのがルールです。
間違えてしまうと負けになります。
スクリプトを作ってみましょう
FizzBuzz をコードで作るのはとても簡単で、初心者でもできますので、是非一緒にやってみましょう。
僕は Javascript でやりたいと思います。
Javascript は Chrome のコンソールに直接書いてすぐに実行できますので、便利です。
まずは、1 から 99 までの for ループを作りましょう。
そのループの中で、数字をそのまま書き出します。(Fizz や Buzz は後でやります)
コンソールで実行する場合、 console.log を使いますが、プログラミング言語によって、echo や print なども使えます。
これをコンソールで実行する場合、1 から 99 までの数字が全部出力されます。

Fizz と Buzz を入れるには?
3 で割れる場合、”Fizz”
5 で割れる場合、”Buzz”
3 と 5 で割れる場合、”FizzBuzz”
そして、どれにも当てはまらない場合、 数字そのまま
それをコードにそのまま書くと、以下のような感じになります。
結果を見ると・・・

ダメですね…
15 の場合、Fizz も Buzz も FizzBuzz も出てしまった。何というバグ。
なお、コードが整っていないですね。バグを修正しようと思っても、更にわかりにくくなりそう…
考え直しましょう!
まず、「出力値」の変数を作りましょう。その変数に空っぽな文字列も入れてみます。
var output = “”;
のような感じで。
もし、3で割れる場合、その output 変数に “Fizz” を追加しましょう。
もし、5で割れる場合、その output 変数に “Buzz” を追加しましょう。
これで、Fizz も Buzz も FizzBuzz も、対応できますよね。
なお、上記のチェック後、その output の変数の文字列が空っぽであれば、数字を書き出せばいいとなりますよね。
結果を見ると・・・
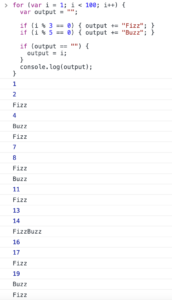
完璧です!
なお、とてもわかりやすいコードになりましたので、ゲームのルールを変更したバージョンもすぐに作成できますね。
まとめ
何かのプログラムやスクリプトを作る場合、書き方は様々あります。
ただし、プログラマーは日常、わかりやすくて簡潔なコードを書くことはとても大事です。
直感でいくと、バグだらけのわかりにくいコードになる恐れはありますので、何かの挑戦に取り組む前に、進め方を一度考えてから進んだほうがいいでしょうね。
これからも頑張っていきましょう!