AIで音楽を作ってみました
こんにちは。開発担当のマットです。
このあいだ、友達を家に招いたら、楽器を持ってきました。
持ってきたものは、ディジュリドゥでした。

ディジュリドゥが母国のオーストラリアの先住民が使う吹奏楽器です。
子供の頃、叔父の家に一つあったのでちょっとだけ使ったことがありますが、
不慣れのディジュリドゥを吹いてみるとすぐに息が切れて、中々演奏できませんでした。
楽器を使って、音楽を作れたらカッコいいな〜と思ったら…
パソコンならできる?
実際の楽器なら演奏できる能力がない。
ただし、パソコンなら、ソフトウェアを使って、何かを作曲できそう!
と思ってみて、GarageBand という音楽制作ソフトを開いてみて、やってみたら・・・
なんじゃこれ・・・・完全に駄目ですね。真剣にやってみます。
GarageBand の使い方をなんとか勉強して、20分掛けてみたら、以下の曲を作れました。
なにこれ・・・w
壁が見えてきました
まず、GarageBand の音楽作成ソフトの使い方を覚えないといけない壁が一つ。
つぎ、音楽論など、音楽を作成する時に必要な最低限の知識を覚えないといけないので、壁が二つ。
そして、元々センスがない自分がなんとか、センスを付けないといけない壁が三つもあります。
難しいですね。
今どきの壁を破るAI
音楽なら、AIが作れますよね〜
ネットで探してみたら、多数の音楽生成のAIを見つけましたけど、自分が求めているものを見つけられませんでした。ほとんどのサービスが決められているテーマや楽器の組み合わせを使って、音楽を作れる便利なサービスですが、僕は求めていたのはクリエイティビティ。
・「背景を和太鼓にする」
・「テンポをちょっと落とす」
・「途中でバイオリンのソロを入れる」
など・・・このようなことをお願いしたら、やってくれるAIが欲しかったです。
話し相手を求めるなら・・・ChatGPT
このような人間の言葉を理解してくれるのは ChatGPT でしょう。
ChatGPT で完全に思う通りの音楽を作ってみることにしました。
まず、簡単な MIDI ファイルを作ってくれるようお願いしてみたら、以下の返答をもらいました。
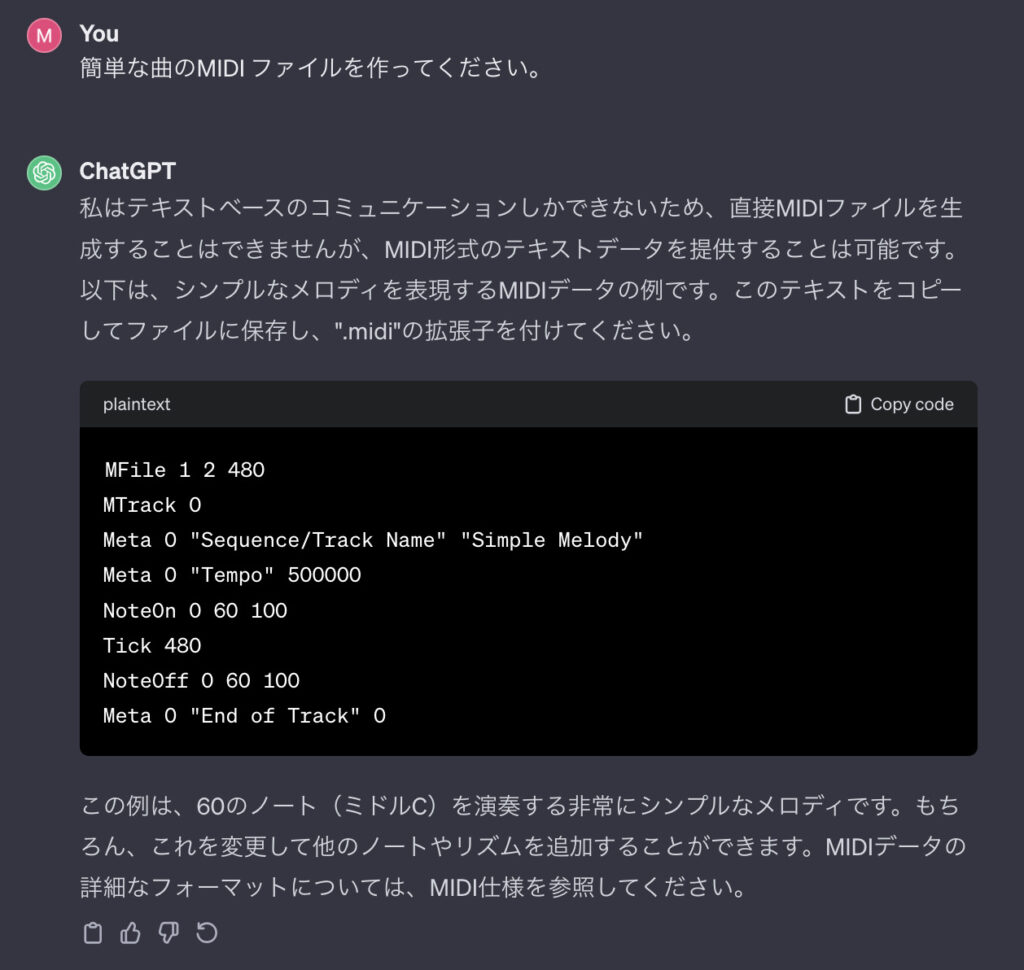
「よかった!簡単にできる!」と思ったら、ChatGPT が嘘をついていました。
ファイルに保存して、.midi の拡張子を付けても、使い物になりませんでした。
よくよく調べてみたら、参考となった別のプロジェクトを見つけました。
全く別の形式なものを ChatGPT に作ってもらって、
それを pythonのライブラリーで変換しなければならない。
python で変換…(大変になってきた)
かなり、大変なことになってしまいましたが、Google Colab で python のスクリプトをコピーして、
ChatGPT に、新たな曲をその形式で求めて実行してみます。

ChatGPT に「複数な楽器を同時に演奏する曲」をお願いしてみました。
何度も何度も繰り返してみました。時には、フォーマットが不正な回答だった。
時には、複数の楽器の演奏があったけど、同時演奏ではなかったなど。
何度も頑張ってやったら、やっと、一つの曲をなんとか作れました。
フルートはかなりの耳障りですが・・・・ChatGPT に音楽を作ってもらったことでなんとか嬉しい気持ちです。
AIの未来
ChatGPT は言語専用のAIですが、実は Google の MusicFX も見つかりました。
日本では使えないツールですが、オーストラリアからアクセスしてみたら、ログインができて、使うことができました。
このツールを使えば、言葉だけで音楽を生成することができます。
まずは、
1)「Caribbean relaxing music with snare drums」(スネアドラムを使ったカリブ海風のくつろげる音楽)
次は、
2) 「Opera with Electric Guitars」(エレキギターを使ったオペラ)
最後は、もともと作りたかったもの
3) 「Rock and Roll with a Didgeridoo」(ディジュリドゥを使ったロックンロール)
まとめ
MusicFXの結果がかなり優れていて、びっくりはしましたけど、その反面、簡単な MIDI ファイルを作るだけでも大苦労でした。
今後、AIが進化するに連れ、このようなツールが数多くなって、力強くなると思います。
いずれ、僕のような音楽の初心者でも、完全にいいものを作曲できる日を楽しみにしています。