[Solr]Jaegarと連携させて分散検索処理を追跡する
はじめに
Solr を Jaeger と連携させて分散検索処理を追跡することができます。
https://solr.apache.org/guide/solr/latest/deployment-guide/distributed-tracing.html
Jaeger は分散トレーシングのツールです。
SolrCloud で複数のノードによる分散インデックス・分散検索を利用するときに、どのノードからどのノードへどんなリクエストが送られたか、どのノードでどの処理にどのくらい時間が掛かったかを追跡でき、これらの情報をパフォーマンスの改善などに利用できます。
Jaegerの起動
Jaegerのバイナリをダウンロードサイトからダウンロードして展開し、以下のコマンドを実行します。
./jaeger-all-in-one --collector.zipkin.host-port=:9411
JaegerTracerConfiguratorの設定
solr.xml に以下を追加します。
<tracerConfig name="tracerConfig" class="org.apache.solr.jaeger.JaegerTracerConfigurator"/>それ以外のパラメータは Solr 起動時に環境変数で渡します。
bin/solr start -cloud -p 8983 -Denable.packages=true -Dsolr.modules=jaegertracer-configurator -DJAEGER_SAMPLER_TYPE=const -DJAEGER_SAMPLER_PARAM=1
プロダクション環境で全クエリを追跡したくはないときは JAEGER_SAMPLER_TYPE に probabilistic などを指定します。今回は動作確認なので const を指定して全部を対象としています。
JAEGER_SAMPLER_PARAM=1を指定しないとサンプリングが実行されません。
クエリの実行と追跡結果の表示
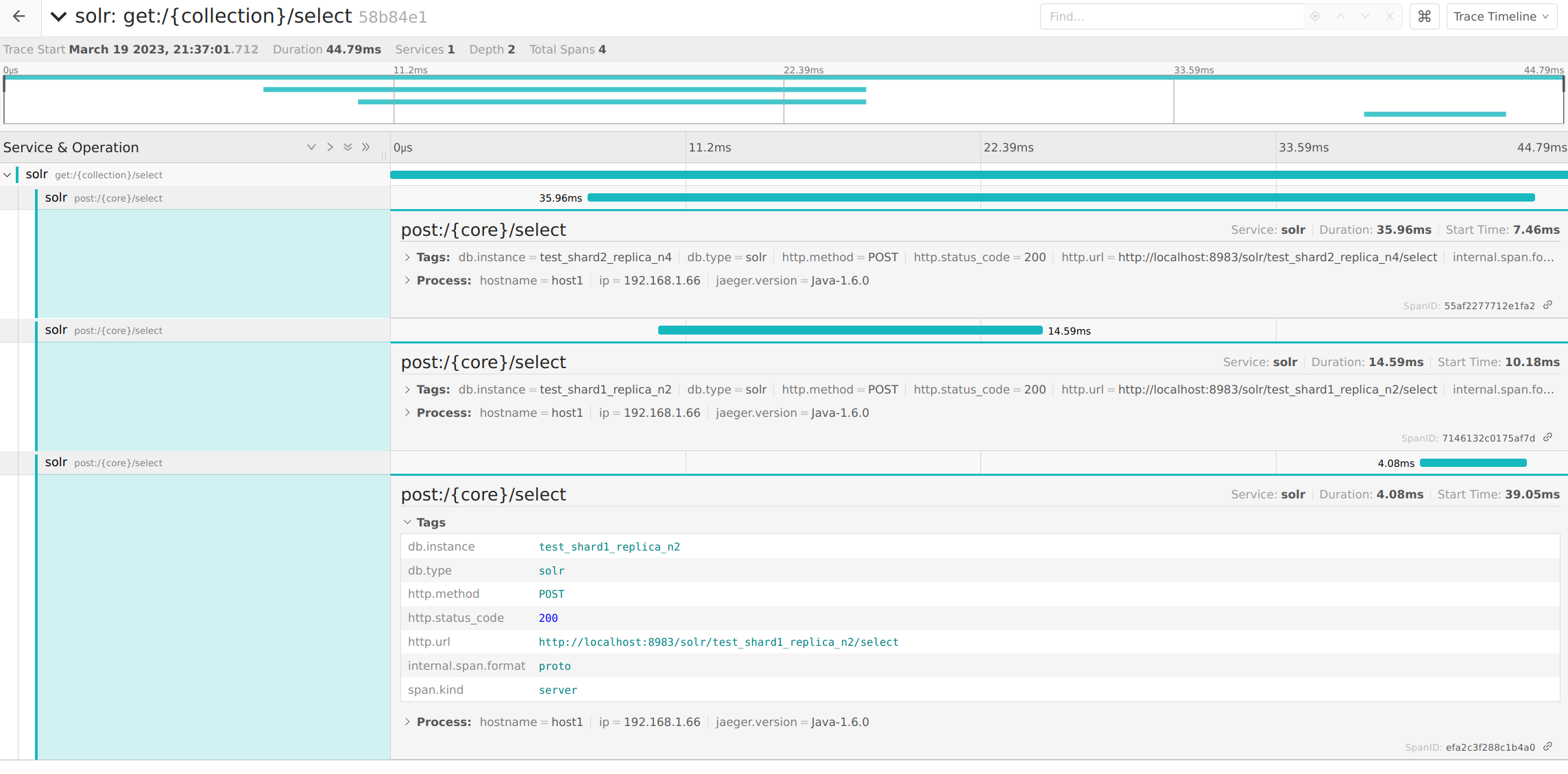
この実験のために2レプリカずつの2シャードのコレクションを作成しました。準備が整ったら Solr Admin UI で何かクエリを実行してから Jaeger UI ( http://localhost:16686/ )にアクセスします。
以下は追跡結果のタイムライン表示の例です。
2023-03-19 12:37:01.732 INFO (qtp487416600-120) [c:test s:shard2 r:core_node7 x:test_shard2_replica_n4] o.a.s.c.S.Request webapp=/solr path=/select params={df=_text_&distrib=false&fl=id&fl=score&shards.purpose=16388&start=0&fsv=true&q.op=OR&shard.url=http://localhost:8983/solr/test_shard2_replica_n4/|http://localhost:8983/solr/test_shard2_replica_n5/&rows=10&rid=localhost-6&version=2&q=*:*&omitHeader=false&NOW=1679229421713&isShard=true&wt=javabin&useParams=&_=1678885506788} hits=4562 status=0 QTime=11
2023-03-19 12:37:01.733 INFO (qtp487416600-15) [c:test s:shard1 r:core_node6 x:test_shard1_replica_n2] o.a.s.c.S.Request webapp=/solr path=/select params={df=_text_&distrib=false&fl=id&fl=score&shards.purpose=16388&start=0&fsv=true&q.op=OR&shard.url=http://localhost:8983/solr/test_shard1_replica_n2/|http://localhost:8983/solr/test_shard1_replica_n1/&rows=10&rid=localhost-6&version=2&q=*:*&omitHeader=false&NOW=1679229421713&isShard=true&wt=javabin&useParams=&_=1678885506788} hits=4676 status=0 QTime=8
2023-03-19 12:37:01.753 INFO (qtp487416600-120) [c:test s:shard1 r:core_node6 x:test_shard1_replica_n2] o.a.s.c.S.Request webapp=/solr path=/select params={df=_text_&distrib=false&shards.purpose=64&q.op=OR&shard.url=http://localhost:8983/solr/test_shard1_replica_n2/|http://localhost:8983/solr/test_shard1_replica_n1/&rows=10&rid=localhost-6&version=2&q=*:*&omitHeader=false&NOW=1679229421713&ids=22,11,12,24,13,14,15,16,20,10&isShard=true&wt=javabin&useParams=&_=1678885506788} status=0 QTime=1
それぞれのリクエストは上記のログに対応しています。
shard1 と shard2 に id だけを取得するリクエストを並行して投げて、その後、得られた id のリストを統合して結果作成用のリクエストを投げていることが分かります。