はじめに
Solr 8.6 以降 Data Import Handler (DIH)が deprecated となり、外部パッケージ化されました。
https://cwiki.apache.org/confluence/display/SOLR/Deprecations
https://github.com/rohitbemax/dataimporthandler
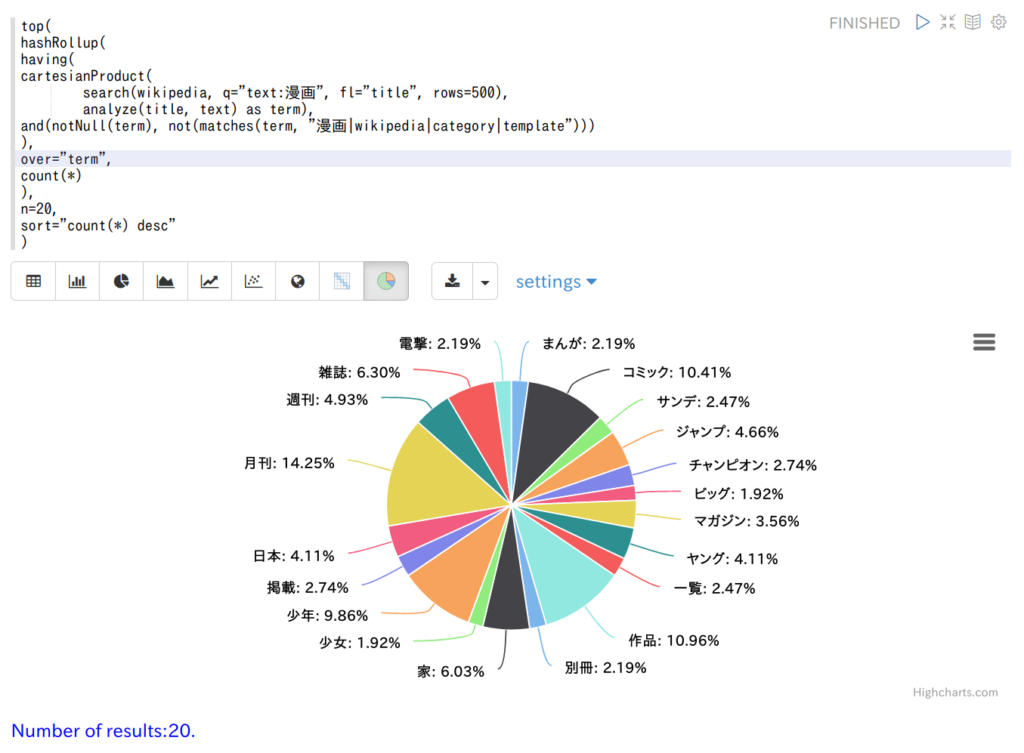
以前やったように Wikipedia の記事をインポートする作業を通じて、外部パッケージ化された DHI を利用する方法を確認しました。
Wikipedia のデータダウンロード
https://dumps.wikimedia.org/jawiki/
の latest から jawiki-latest-pages-articles.xml.bz2 をダウンロードして展開しておきます。
DIHをSolrにインストールする
パッケージ機能を有効にして Solr を起動
$ bin/solr -c -Denable.packages=true
data-import-handler パッケージのリポジトリを追加
$ bin/solr package add-repo data-import-handler "https://raw.githubusercontent.com/rohitbemax/dataimporthandler/master/repo/"
data-import-handler パッケージインストール
$ bin/solr package install data-import-handler
Wikipedia インポート用のコレクション設定
$ cd solr-8.10.0/server/solr/configsets
$ cp -r _default wikipedia
$ vi wikipedia/conf/data-config.xml
DIH 用の設定ファイル data-config.xml を作成します。
<dataConfig>
<dataSource type="FileDataSource" encoding="UTF-8" />
<document>
<entity name="page"
processor="XPathEntityProcessor"
stream="true"
forEach="/mediawiki/page/"
url="data/jawiki-latest-pages-articles.xml"
transformer="RegexTransformer,DateFormatTransformer">
<field column="id" xpath="/mediawiki/page/id" />
<field column="title" xpath="/mediawiki/page/title" />
<field column="revision" xpath="/mediawiki/page/revision/id" />
<field column="user" xpath="/mediawiki/page/revision/contributor/username" />
<field column="userId" xpath="/mediawiki/page/revision/contributor/id" />
<field column="text" xpath="/mediawiki/page/revision/text" />
<field column="timestamp" xpath="/mediawiki/page/revision/timestamp" dateTimeFormat="yyyy-MM-dd'T'hh:mm:ss'Z'" />
<field column="$skipDoc" regex="^#REDIRECT .*" replaceWith="true" sourceColName="text"/>
</entity>
</document>
</dataConfig>
読み込み対象を data/jawiki-latest-pages-articles.xml と指定しているので、記事ファイルを ${SOLR}/server/data/jawiki-latest-pages-articles.xml としてコピーしておきます。
設定ファイルのセットを ZooKeeper 上にアップロードします。
(cd conf && zip -r - *) |curl -X POST --header "Content-Type:application/octet-stream" --data-binary @- "http://localhost:8983/solr/admin/configs?action=UPLOAD&name=wikipedia"
コレクション wikipedia を作成して DIH を有効にする
先程アップロードした設定ファイルを指定して、コレクション wikipedia を作成します。
$ curl "http://localhost:8983/solr/admin/collections?action=CREATE&name=wikipedia&numShards=1&collection.configName=wikipedia"
コレクション wikipedia に data-import-handler をデプロイします。
$ bin/solr package deploy data-import-handler -y -collections wikipedia
Wikipedia の記事をインポートする
full-import をスタート。
$ curl "http://localhost:8983/solr/wikipedia/dataimport?command=full-import"