SolrCloudのリーダー再選出の動作を確認する
はじめに
前回の記事ではシャードを構成する複数のレプリカの中からリーダーが選出される仕組みを解説しました。この記事では、実際に動いているSolrCloudを使って、特定のノードがダウンしたときにリーダーが切り替わる動作を確認してみます。
SolrCloudの構成
- サーバ3台、サーバ毎に Solr 1プロセス
- コレクション名 test のコレクションを作成
- test コレクションは shard1 と shard2 の2つのシャードを含む
- 各シャードはそれぞれ3つのレプリカ(それぞれ別のSolrノードで動く)を含む

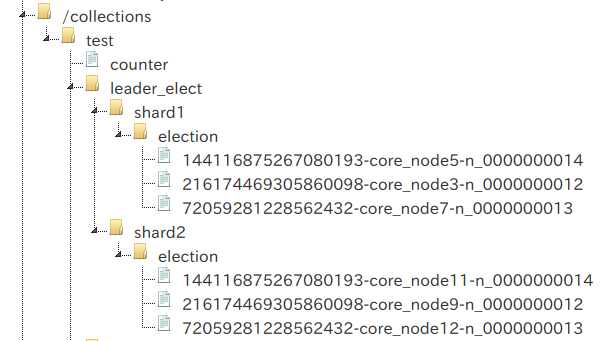
| コア名 | ノード | シリアル番号 | 備考 |
| core_node3 | 172.19.0.7:8985 | 12 | リーダー |
| core_node5 | 172.19.0.6:8983 | 14 | |
| core_node7 | 172.19.0.5:8984 | 13 |
| コア名 | ノード | シリアル番号 | 備考 |
| core_node9 | 172.19.0.7:8985 | 12 | リーダー |
| core_node11 | 172.19.0.6:8983 | 14 | |
| core_node12 | 172.19.0.5:8984 | 13 |
リーダーがダウンしたとき
ノード 172.19.0.7:8985 (core_node3, core_node9)を落としてみます。
それまでのリーダー(シリアル番号12)の次に若い番号(13)を持つcore_node7およびcore_node12が新しいリーダーに選ばれています。

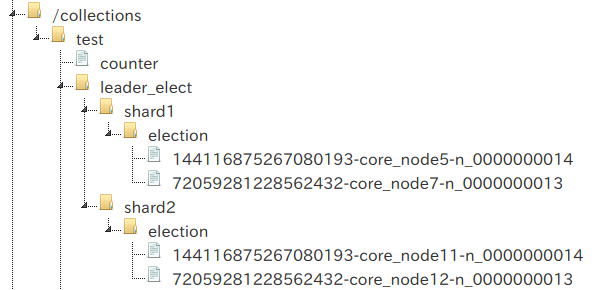
| コア名 | ノード | シリアル番号 | 備考 |
| core_node3 | 172.19.0.7:8985 | 12 | ダウン |
| core_node5 | 172.19.0.6:8983 | 14 | |
| core_node7 | 172.19.0.5:8984 | 13 | リーダー |
| コア名 | ノード | シリアル番号 | 備考 |
| core_node9 | 172.19.0.7:8985 | 12 | ダウン |
| core_node11 | 172.19.0.6:8983 | 14 | |
| core_node12 | 172.19.0.5:8984 | 13 | リーダー |
ダウンしたノードが復帰したとき
ダウンさせていた 172.19.0.7:8985 (core_node3, core_node9)を復帰させます。
リーダーに変更は無く、core_node3とcore_node9は新しい番号15をそれぞれ割り当てられます。

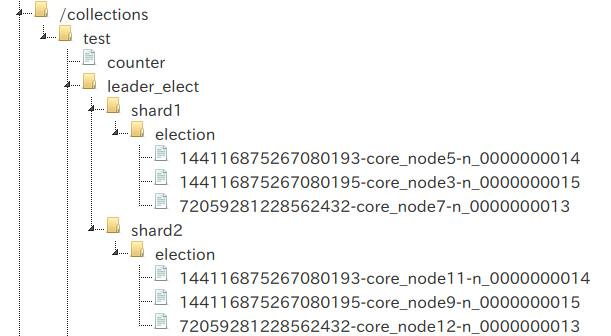
| コア名 | ノード | シリアル番号 | 備考 |
| core_node3 | 172.19.0.7:8985 | 15 | 復帰 |
| core_node5 | 172.19.0.6:8983 | 14 | |
| core_node7 | 172.19.0.5:8984 | 13 | リーダー |
| コア名 | ノード | シリアル番号 | 備考 |
| core_node9 | 172.19.0.7:8985 | 15 | 復帰 |
| core_node11 | 172.19.0.6:8983 | 14 | |
| core_node12 | 172.19.0.5:8984 | 13 | リーダー |
リーダーを意図的に変更する
まずcore_node3をpreferredLeaderに指定します。
curl 'http://172.19.0.6:8983/solr/admin/collections?action=ADDREPLICAPROP&shard=shard1&collection=test&replica=core_node3&property=preferredLeader&property.value=true'
REBALANCELEADERSを実行。
curl 'http://172.19.0.6:8983/solr/admin/collections?action=REBALANCELEADERS&collection=test'
{
"responseHeader":{
"status":0,
"QTime":3053},
"Summary":{
"Success":"All active replicas with the preferredLeader property set are leaders"},
"successes":{
"shard1":{
"status":"success",
"msg":"Successfully changed leader of slice shard1 to core_node3"}}}
shard1のリーダーがcore_node3に変更されました。


FORCELEADER
FORCELEADERは障害等何らかの理由でリーダー不在の状態ができてしまった場合に強制的にリーダーを割り当てるためのコマンドです。リーダーが居ない状態を意図的に作るのは難しいので、正常な状態のシャードに対して FORCELEADER を実行するとどうなるか試してみました。
curl 'http://172.19.0.6:8983/solr/admin/collections?action=FORCELEADER&collection=test&shard=shard2'
{
"responseHeader":{
"status":500,
"QTime":35},
"error":{
"metadata":[
"error-class","org.apache.solr.common.SolrException",
"root-error-class","org.apache.solr.common.SolrException"],
"msg":"The shard already has an active leader. Force leader is not applicable. State: shard2:{
(略)
"code":500}}
指定されたシャードにはリーダーが居るのでFORCELEADERの実行はできませんと怒られてしまいました。
おわりに
SolrCloudのクラスタはZooKeeperと連携していて、リーダーがダウンしたら自動的に新しいリーダーが選ばれてなるべくダウンタイムが小さくなるように工夫されている、という漠然とした理解から一歩進むために、具体的なリーダー選出のロジックを調べました。ZooKeeperの分散アプリケーションのコーディネート機能を使って案外シンプルなロジックで実装されていることが分かりました。この理解を持った上でリーダー調整用のAPIを上手に使えば、稀に発生するクラスタ異常にもうまく対処することができそうです。