Apache Solr を Eclipse でリモートでデバッグ
はじめに
先日、久しぶりに全文検索エンジン Apache Solr に触れる機会がありました。
現時点の最新版は 7.5 です(この記事を書いている間に 7.6 がリリースされました)。以前に扱ったことのある 5.5 からはかなり色々なところが変わっているようです。
Solr は OSS なので変更点の詳細を追いかけたければソースを読めばいいのですが、Solr くらいの規模のソフトウェアとなるとソースを読むだけでは取っ掛かりが掴みにくいことも有ります。たとえば、この factory オブジェクトが生成したのはどの具象クラスなんだ、とか、この if 文の分岐はどっちが使われるんだ、とか。そういう場合にはデバッガが役に立ちます。
今回は以下のような構成でデバッガを動かすための手順をまとめました。
- Solr 7.5 バイナリパッケージ(稼働用)
- Solr 7.5 ソースパッケージ(デバッガ参照用)
- Eclipse IDE for Java Developers Version 2018-09
Solr のインストール
-
- 公式サイトからsolr-7.5.0.tgzをダウンロード。
- 展開
$ tar zxf solr-7.5.0.tgz $ cd solr-7.5.0
- サンプル設定で起動
$ bin/solr -e cloud (略) To begin, how many Solr nodes would you like to run in your local cluster? (specify 1-4 nodes) [2]: 1 (略) Please enter the port for node1 [8983]: (略) Please provide a name for your new collection: [gettingstarted] test (略) How many shards would you like to split test into? [2] 1 (略) How many replicas per shard would you like to create? [2] 1 (略) Please choose a configuration for the test collection, available options are: _default or sample_techproducts_configs [_default] (略)
- Solr を一旦停止しておく
$ bin/solr stop -all
Solr のソースを Eclipse にインポート
- 公式サイトからsolr-7.5.0-src.tgzをダウンロード。
- 展開
$ mkdir solr-src $ cd solr-src $ tar zxf solr-7.5.0-src.tgz $ mv solr-7.5.0 solr-7.5.0-src $ cd solr-7.5.0-src
- Eclipse のプロジェクトとして読み込めるようにビルド
$ ant eclipse
- インポート
- 「ファイル」→「インポート」→「既存プロジェクトをワークスペースへ」→「次へ」
- 「ルート・ディレクトリの選択」で solr-src/solr-7.5.0-src を指定→「完了」
デバッグ開始
-
- Solr スタート
リモートプロセスのデバッグなので java コマンドのオプションを指定して JDWP を利用します。
$ bin/solr start -c -p 8983 -s example/cloud/node1/solr -a "-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=6900"
suspend=y を指定するとデバッガが接続するまで実行を中断してくれます。ただし180以内に起動が完了しないと Solr が起動失敗と判断して自らプロセス終了してしまうので、それまでに以下の手順でデバッガを接続しなければなりません。
- デバッガ起動
- 「実行」→「デバッグの構成」
- プロジェクト solr-7.5.0 指定→ポート 6900 指定→「デバッグ」
動作確認
今回は Solr 6 で追加された ExtractingRequestHandler を試してみます。
このハンドラは PDF などのバイナリファイルからテキストを抽出してインデックスを作成するためのものです。solrconfig.xml では以下のように定義されています。
<requestHandler name="/update/extract"
startup="lazy"
class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults">
<str name="lowernames">true</str>
<str name="fmap.meta">ignored_</str>
<str name="fmap.content">_text_</str>
</lst>
</requestHandler>
RequestHandler のメインの処理は handleRequestBody ですが、これは ExtractingRequestHandler の親クラスである ContentStreamHandlerBase クラスで定義されているので、そちらにブレイクポイントを設定しておきます。
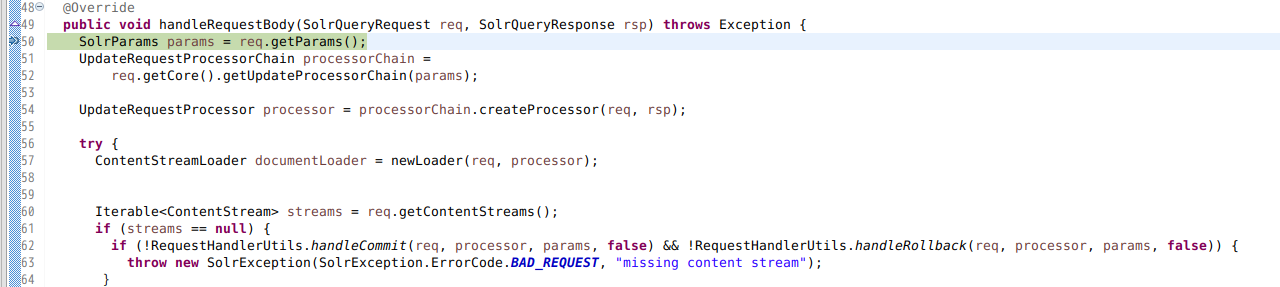
そして PDF ファイルを post コマンドで送信します。
$ bin/post -c test -params "extractOnly=false&wt=json&indent=true" -out yes example/exampledocs/solr-word.pdf
指定しておいた場所でブレイクされます。
あとは普通にデバッガを使っていくだけです。
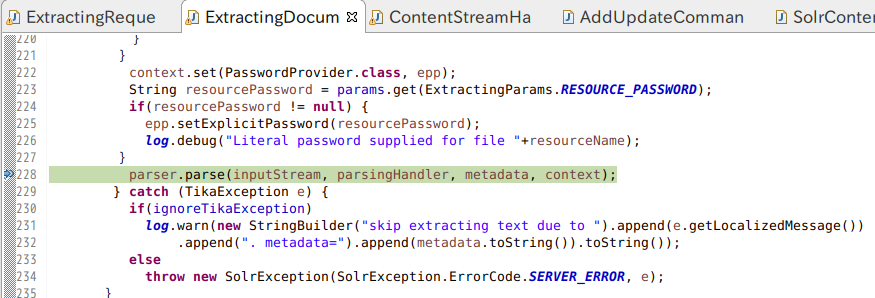
たとえば ExtractingDocumentLoader のこの行で変数の内容を確認すると、
実行時パラメータとして extractOnly=false だけを指定した状態では parser として AutoDetectParser、parsingHandler として SolrContentHandler が使われることが分かりました。
metadata としてどんな情報が抽出されるのかも良く分かります。
最後に
Solrのリモートデバッグは簡単です。Solr 内部の理解を深めるのに役立てたいと思います。