Solr の Kuromoji を extended で使うとインデックスサイズが予想以上に小さくなる問題について
前回得られた、Kuromoji の mode を extended にした場合にインデックスサイズが最も小さくなるという不思議な結果を調査しました。
mode=search と mode=extended の違いは未知語の扱いです。 なので、未知語を含むクエリがどのように扱われるのかを確認しました。
【mode=search の場合】
"rawquerystring":"title:西沙諸島 AND text:パラセル諸島"
"parsedquery":"+title:西沙諸島 +(text:パラセル text:諸島)"
【mode=extended の場合】
"rawquerystring":"title:西沙諸島 AND text:パラセル諸島"
"parsedquery":"+title:西沙諸島 +text:諸島"
未知語が1-gramに分割されてインデックスサイズが多少大きくなることを予想していたのに、実際は逆に未知語が落とされてしまっています。
そこで、mode=search と mode=extended とで「パラセル諸島」を形態素解析した結果を比べてみました。

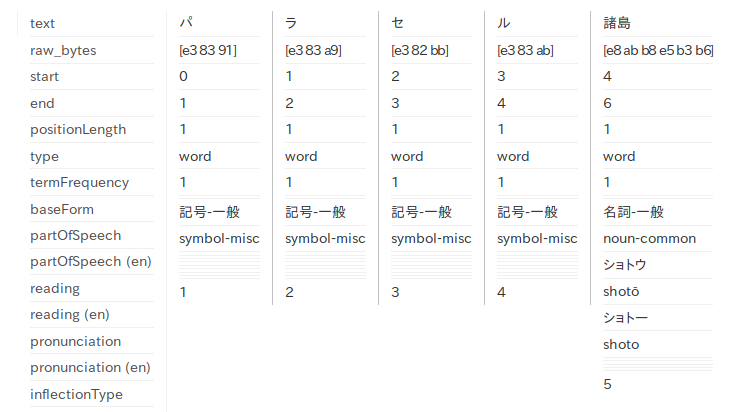
mode=search では「パラセル」が名詞-一般となっており、mode=extended では「パラセル」が1文字ずつに分解されてそれぞれが記号-一般となっています。分解のされ方はどちらも期待通りです。形態素解析に問題が無さそうなので、怪しいのは形態素解析後のフィルタということになります。おそらくストップワードに引っ掛かっているのでしょう。
設定ファイルの lang/stoptags_ja.txt を確認すると、記号-一般がストップワードとして定義されていました。
# symbol-misc: A general symbol not in one of the categories below.
# e.g. [○◎@$〒→+]
記号-一般
そこで、この行をコメントアウトした configset (それ以外は全く同じ)を作り、wikipedia-ja のインデックスを作成しました。
4.2G example/cloud/node1/solr/wikipedia-ja-extended2_shard1_replica_n1
2.1G example/cloud/node1/solr/wikipedia-ja-extended_shard1_replica_n1
3.1G example/cloud/node1/solr/wikipedia-ja-normal_shard1_replica_n1
3.1G example/cloud/node1/solr/wikipedia-ja-search_shard1_replica_n1
予想通り、4.2GBとmode=searchよりもインデックスサイズが大きくなりました。形態素解析の結果は以下の通りです。
"rawquerystring":"title:西沙諸島 AND text:パラセル諸島"
"parsedquery":"+title:西沙諸島 +(text:パ text:ラ text:セ text:ル text:諸島)"
インデックスサイズが大きくなったのは、単に未知語が1-gramに分割されただけではなく、他の記号類もストップワードから外れてインデックスに入ってしまったからだと思います。 1-gram に分割したときの品詞を変更できるようになっていればいいのですが、ざっと調べた感じではそうはなっていないようです。 その弊害を考えると、mode=extended はちょっと使い勝手が悪いと言えるかもしれません。