[Solr] Lucene8.1に同梱されるようになったLukeを使う
はじめに
LukeはLucene用のインデックスブラウザです。SolrはLuceneのインデックスを利用しているので、SolrのインデックスをLukeでブラウズすることができます。
Lukeは従来Luceneから見るとサードパーティのソフトウェアであったので、その時々のLuceneのバージョンに合わせてコンパイルが必要で、さらに近年ではLukeのメンテナンスが追いついていない部分もあり、実際に使うにはいろいろ手間が必要な状態になっていました。
そのLukeがLucene 8.1(Solr 8.1)でLuceneのモジュールとして取り込まれました。 この長い長いチケットを見れば分かるように、様々な方の尽力の賜物です。
Luke の特徴
- インデックスされている文書の閲覧
- インデックスされているタームを、頻度順で表示
- 検索の実行と結果の分析
- 特定の文書の削除
- ドキュメントのフィールド構成の変更と再インデックス
- インデックスの最適化
起動
Luke の起動に必要な lucene-luke.jar は Solr の配布物には含まれていないので Lucene をダウンロードします。 ダウンロードしたら展開して luke/luke.sh を実行します。これだけで良くなったので、以前に比べると断然使いやすくなりました。
tar zxf lucene-8.1.0.tgz cd lucene-8.1.0 luke/luke.sh
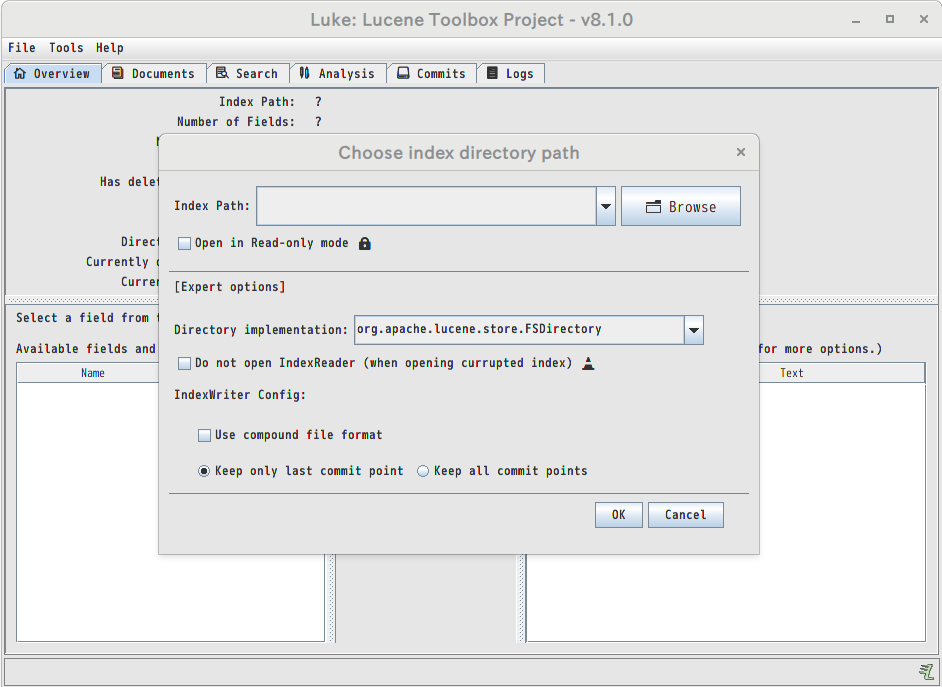
起動直後に開くダイアログで、Solrのインデックスが格納されているディレクトリ指定します。
インデックスブラウザ
Overviewのタブでは、インデックスのフィールド毎に頻度の高い順にタームを表示することができます。
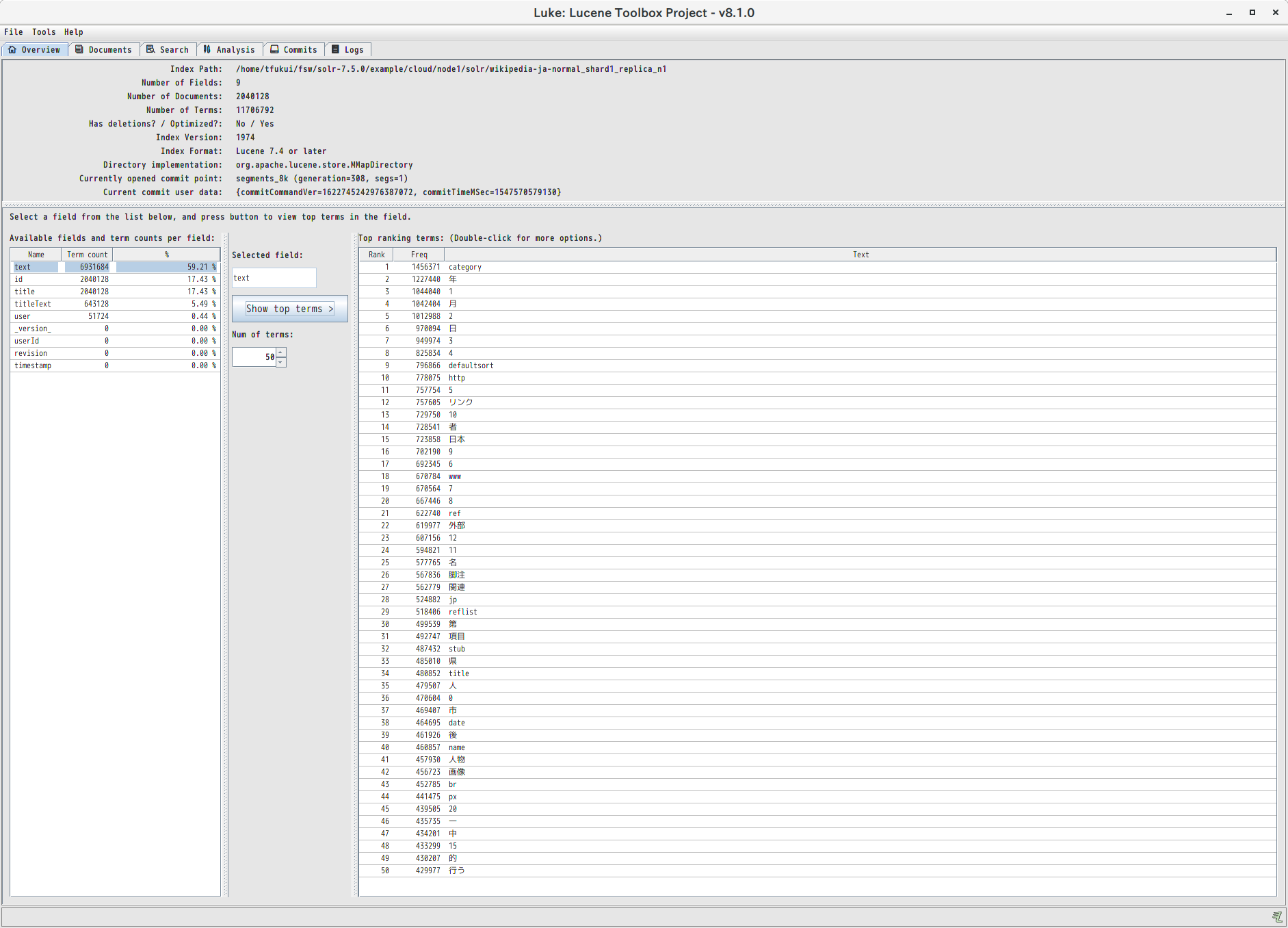
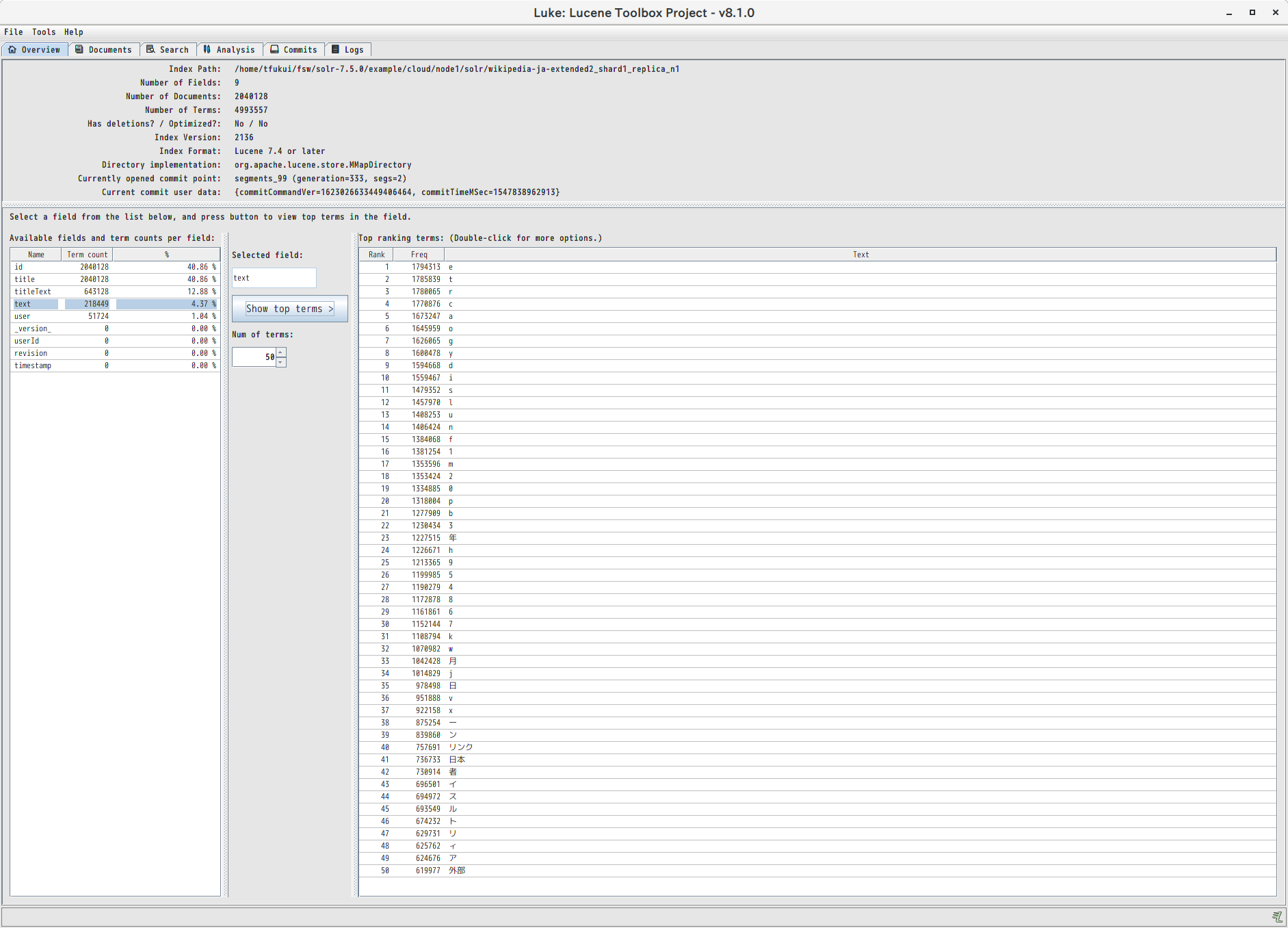
たとえば同じ Wikipedia-ja をインデックスした場合でも、Kuromoji の normal モードを使うか extended モードを使うかでインデックスの内容が大きく異なることが分かります。
extended モードでは未知語が uni-gram に分割されるという特性を反映して、上位の多くを “e”, “t”, “r” などのアルファベット1文字のタームが占めています。normal モードでは “年”, “月”, “日” や数字など1文字のタームに加えて”category”,”リンク”,”外部”,”脚注”などWikipediaで頻出の用語も上位に来ています。
おわりに
上に挙げたような、インデックスの内容を直接参照するような使い方の他にも
- 特定の文章が期待通りのタームに分割されているか調べる
- 期待通りの検索結果を得るためのクエリを試行錯誤する
- Analyzerを切り替えたときの形態素解析結果の違いを調べる
など、開発に役立つ機能が満載です。
使いやすい形で配布されるようになった Luke を活用していきたいと思います。