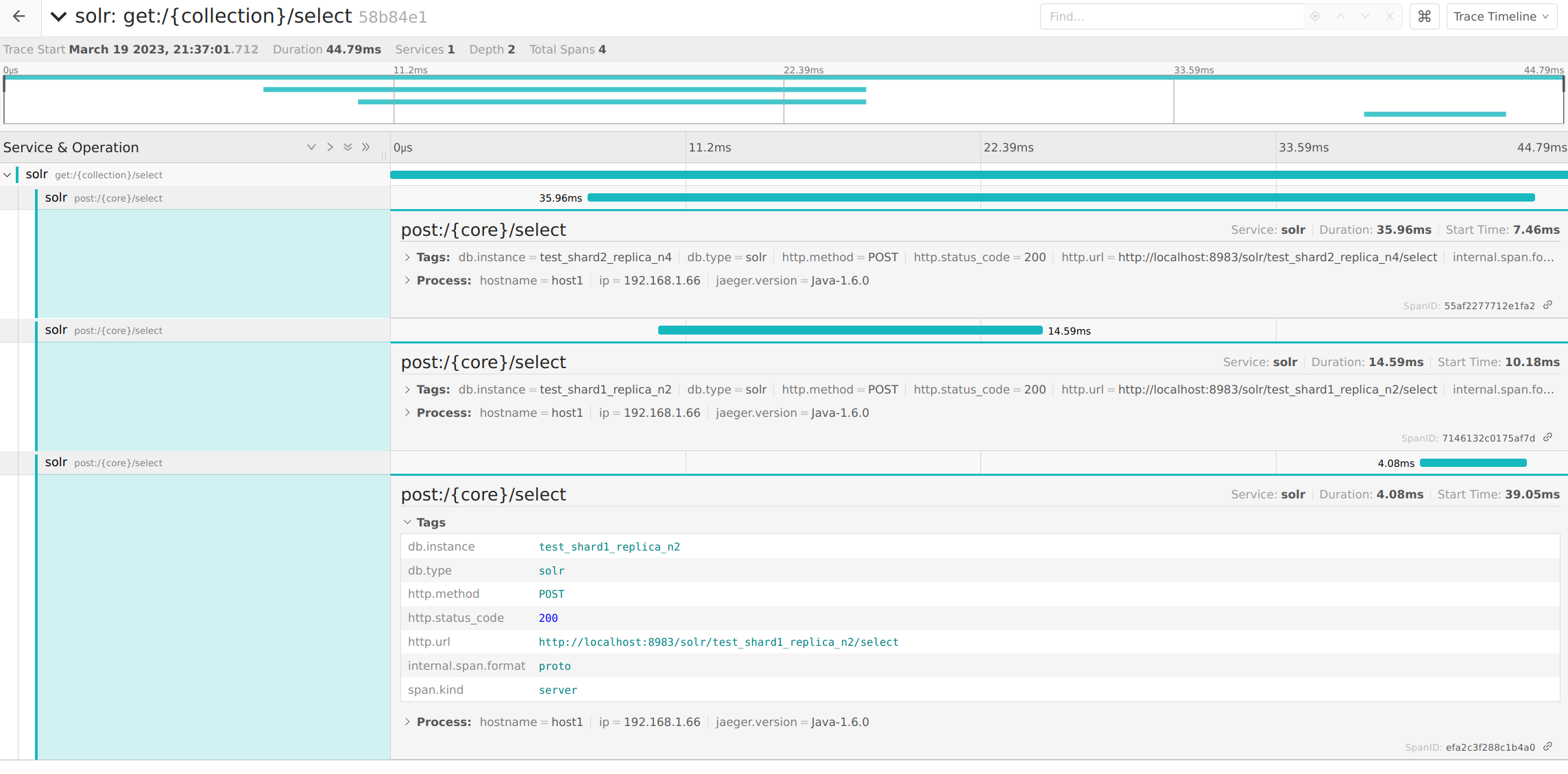
Solrによる検索環境を構築するにあたって、スキーマの設定ファイルを作るところは意外と面倒です。
その部分を試しに ChatGTP に手伝ってもらいました。
以下の内容で依頼しました。
Apache Solr で以下の文書のインデックスを作成します。デフォルトのスキーマ設定にスキーマAPIを使って必要な設定を追加するための JSON ファイルを作成してください。
インデックス対象の文書は以下の形式の JSON ファイルで与えられます。
[{“id”:”10″,”type”:”官公庁”,”area”:”住之江区”,”name”:”軽自動車検査協会大阪主管事務所”,”address”:”住之江区南港東3-4-62″,”address_p”:”34.6164938333333,135.438210722222″},
{“id”:”11″,”type”:”官公庁”,”area”:”住之江区”,”name”:”大阪陸運支局なにわ自動車検査登録事務所”,”address”:”住之江区南港東3-1-14″,”address_p”:”34.6190439722222,135.442191833333″}]
インデックス対象は、いつもの大阪の施設情報です。具体例として与えたのは2レコード分だけですが、以下のように適切なスキーマを作ってくれました。
以下は、Apache Solr でこの JSON ファイルをインデックスするためのスキーマ定義の例です。この例は、id、type、area、name、address、address_p の6つのフィールドをインデックスすることを想定しています。
{
"add-field": [
{
"name": "id",
"type": "string",
"indexed": true,
"stored": true,
"required": true,
"multiValued": false
},
{
"name": "type",
"type": "string",
"indexed": true,
"stored": true,
"required": true,
"multiValued": false
},
{
"name": "area",
"type": "string",
"indexed": true,
"stored": true,
"required": true,
"multiValued": false
},
{
"name": "name",
"type": "text_general",
"indexed": true,
"stored": true,
"required": true,
"multiValued": false
},
{
"name": "address",
"type": "text_general",
"indexed": true,
"stored": true,
"required": true,
"multiValued": false
},
{
"name": "address_p",
"type": "location_rpt",
"indexed": true,
"stored": true,
"required": true,
"multiValued": false
}
]
}
このスキーマ定義によって、以下のようにインデックスを作成することができます。
- Apache Solrの管理画面にアクセスします。
- 左側のメニューから「コアの作成」をクリックして、新しいコアを作成します。
- 新しいコアの名前を入力し、「コアを作成する」をクリックします。
- 新しいコアの管理画面に移動し、「スキーマ」をクリックします。
- 「スキーマ」のページで、「スキーマAPI」をクリックし、「スキーマ定義の追加」をクリックします。
- 上記のスキーマ定義をコピーして、「スキーマ定義の追加」のテキストボックスに貼り付けます。
- 「送信」をクリックしてスキーマを追加します。
- 左側のメニューから「ドキュメント」をクリックして、新しいドキュメントを追加します。
- 新しいドキュメントのJSON形式のデータを入力し、「追加」をクリックしてインデックスを作成します。
- インデックスが作成されたことを確認するために、左側のメニューから「クエリ」をクリックして、クエリを実行して結果を確認します。
短い文字列には string、 長めの文字列には text_general、緯度経度には location_rpt とデータの内容に合わせてフィールドタイプを選んでくれているように見えます。 address_pという名前がヒントになったかもしれないので hoge にして試してみましたが、やはり location_rpt になりました。
このようにインデックス作成までの準備の部分を AI に手伝ってもらえると、いろいろと楽になりそうです。