Solrのドキュメントルーティングで複数階層のシャードキーを指定するとどうなるのか
はじめに
SolrのcompositeIdを使ったドキュメントルーティングではシャードキーを複数指定することができます。シャードキーを複数指定した場合の動作をちゃんと考えたことが無かったので調べてみました。
compositeIdを使ったドキュメントルーティング
compositeIdを使ったドキュメントルーティングではドキュメントIDとシャードキーから計算されたハッシュ値に基づいて、インデッ クス先のシャードが決まります。シャードキーが指定されなければドキュメントIDのハッシュだけが使われます。
1レベルのシャードキー
シャードキーを指定する場合、ドキュメントIDのフィールドを以下のように記述します。
“シャードキー!ドキュメントID”
以前サンプルに利用した大阪市の施設情報のデータの場合、区名に基づいてシャードを分けるには
“中央区!1234”
のようにドキュメントIDのフィールドを指定します。
こうすることで、同じ区の施設データは必ず同じシャードに配置されるようにインデックスされます。
2レベルのシャードキー
2段階目のシャード分けの条件として施設タイプを使うとすると、ドキュメントIDの指定の仕方は以下のようになります。
“中央区!官公庁!1234”
こう書けるところまではドキュメントを読めば書いてあります。ではこう書いた場合に具体的にはどのような配置になるのでしょうか。
ドキュメントIDのハッシュとシャードの対応付け
ハッシュは32ビットです。00000000からffffffffまでの値をシャード数に応じて均等に区分けします。たとえばシャード数が8の場合、以下のように分けられます。
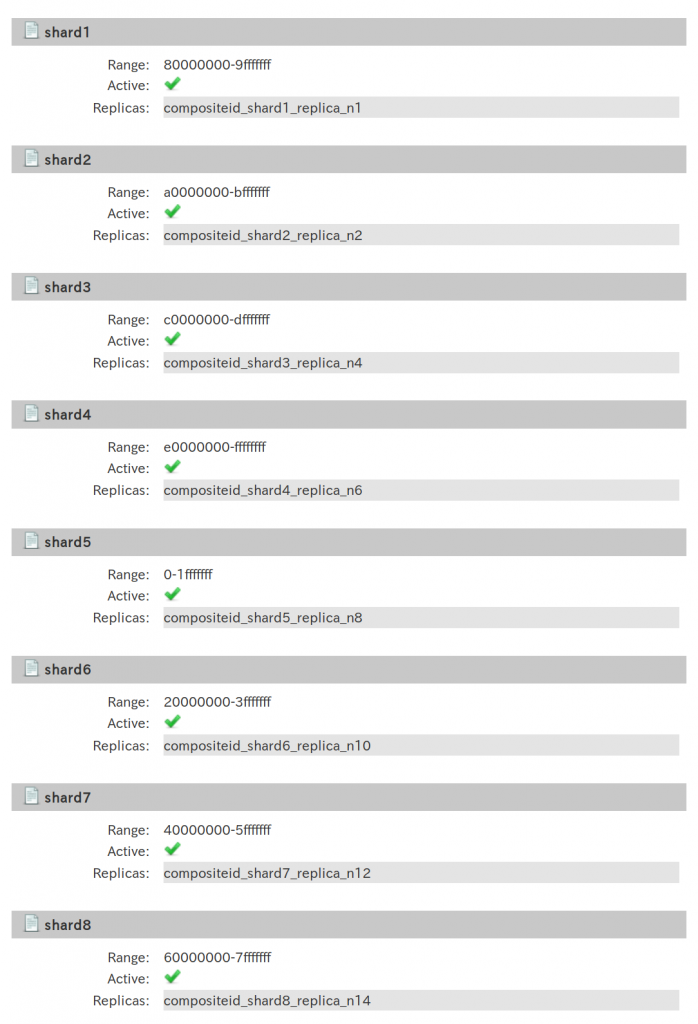
8等分なので上位3ビットで分類するわけです。
| シャード | 最初の3ビット(2進数) | 最初の1桁(16進数) |
| shard1 | 000 | 0〜1 |
| shard2 | 001 | 2〜3 |
| shard3 | 010 | 4〜5 |
| shard4 | 011 | 6〜7 |
| shard5 | 100 | 8〜9 |
| shard6 | 101 | a〜b |
| shard7 | 110 | c〜d |
| shard8 | 111 | e〜f |
シャードキーが指定されたときにハッシュがどう計算されるのか
こちらの記事によると、
シャードキーが1つの場合
ハッシュの上位16ビット:シャードキーのハッシュから
ハッシュの下位16ビット:ドキュメントIDのハッシュから
シャードキーが2つの場合
ハッシュの上位8ビット:シャードキー1のハッシュから
ハッシュの次の8ビット:シャードキー2のハッシュから
ハッシュの下位16ビット:ドキュメントIDのハッシュから
となるようです。
シャードキーを2つ指定したとしても、最上位の8ビットをシャードキー1が占めているため、シャード数が256より小さい限りはシャードキー2は影響を与えることができません。
実際に8シャードのコレクションに2パターンのデータを投入して、シャード毎のレコード数をカウントしてみました。シャードキーが1つの場合も2つの場合も同じになっていることが分かります。
$ head -3 data1.json
[
{"id":"住之江区!158","type":"官公庁","area":"住之江区","name":"軽自動車検査協会大阪主管事務所","address":"住之江区南港東3-4-62"}
{"id":"住之江区!157","type":"官公庁","area":"住之江区","name":"大阪陸運支局なにわ自動車検査登録事務所","address":"住之江区南港東3-1-14"},
$ curl 'http://localhost:8983/solr/compositeid/update?commit=true&indent=true' --data-binary @data1.json -H 'Content-Type: application/json'
$ for i in {1..8}; do curl -s "http://localhost:8983/solr/compositeid/select?q=*:*&rows=0&shards=shard${i}"|jq '.response.numFound'; done
580
509
1471
1203
2092
761
545
2077
$ head -3 data2.json
[
{"id":"住之江区!官公庁!158","type":"官公庁","area":"住之江区","name":"軽自動車検査協会大阪主管事務所","address":"住之江区南港東3-4-62"},
{"id":"住之江区!官公庁!157","type":"官公庁","area":"住之江区","name":"大阪陸運支局なにわ自動車検査登録事務所","address":"住之江区南港東3-1-14"},
$ curl 'http://localhost:8983/solr/compositeid/update?commit=true&indent=true' --data-binary @data1.json -H 'Content-Type: application/json'
$ for i in {1..8}; do curl -s "http://localhost:8983/solr/compositeid/select?q=*:*&rows=0&shards=shard${i}"|jq '.response.numFound'; done
580
509
1471
1203
2092
761
545
2077
ビット数の制限付きでシャードキーを指定する
シャードキーと共にビット数を指定することもできます。たとえば
“中央区/2!官公庁/14!1234”
とすると、
ハッシュの上位2ビット:区名のハッシュから
ハッシュの次の14ビット:施設タイプのハッシュから
ハッシュの下位16ビット:ドキュメントIDのハッシュから
となります。
2ビットということは、区名により4つに分類されるということです。
たとえば8シャード用意されている場合、特定の区は特定の2シャードのどちらかに配置されることになり、そのどちらになるのかは施設タイプにより決定される、という訳です。
このパターンで先程同様にデータを投入すると、シャードごとのレコード数が大きく変化したことが分かります。
$ head -3 data3.json
[
{"id":"住之江区/2!官公庁/4!158","type":"官公庁","area":"住之江区","name":"軽自動車検査協会大阪主管事務所","address":"住之江区南港東3-4-62"},
{"id":"住之江区/2!官公庁/4!157","type":"官公庁","area":"住之江区","name":"大阪陸運支局なにわ自動車検査登録事務所","address":"住之江区南港東3-1-14"},
$ curl 'http://localhost:8983/solr/compositeid/update?commit=true&indent=true' --data-binary @data4.json -H 'Content-Type: application/json'
$ for i in {1..8}; do curl -s "http://localhost:8983/solr/compositeid/select?q=*:*&rows=0&shards=shard${i}"|jq '.response.numFound'; done
578
511
1414
1260
1572
1281
1390
1232
それほど大規模なシステムではない場合、このように少ないビット数で制限を掛けるやり方が、現実的なシャードキーの利用方法になるでしょう。