Solrで日本語版Wikipediaのインデックスを作った場合のサイズをTokenizerの設定毎に調べる
はじめに
Solrで日本語の文書を扱う場合に考えなくてはならないことの一つに、Tokenizerをどれにするか、があります。ざっくり言うと、n-gram(だいたいは2-gram)にするか、形態素解析にするか、です。
それぞれの長所、短所はこんな感じです。
n-gram
長所
- 検索漏れが少ない
- 未知語に強い
短所
- nより短いキーワードを扱えない
- インデックスサイズが大きくなる
- 検索結果のノイズが多い
形態素解析
長所
- 検索結果のノイズが少ない
- インデックスサイズを小さくする余地が大きい
短所
- 未知語に弱い
- 入力キーワードに対する完全一致検索が難しい
双方の長所・短所に出てきたインデックスサイズがどれくらいの差になるのかを日本語版Wikipediaを対象に調べてみました。
SolrにWikipediaを投入する
Wikipediaのダンプデータをダウンロード
https://dumps.wikimedia.org/jawiki/
の latest から jawiki-latest-pages-articles.xml.bz2 をダウンロードして展開しておきます。
configset準備
_default をベースに設定ファイルを用意します。
cp -r server/solr/configsets/_default server/solr/configsets/wikipedia wikipedia/conf/solrconfig.xml に以下を追加
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">solr-data-config.xml</str>
</lst>
</requestHandler>Wikppediaインポート用の DataImportHander の設定 solr-data-config.xml を
https://wiki.apache.org/solr/DataImportHandler#Example:_Indexing_wikipedia
を参考にして作成
<dataConfig>
<dataSource type="FileDataSource" encoding="UTF-8" />
<document>
<entity name="page"
processor="XPathEntityProcessor"
stream="true"
forEach="/mediawiki/page/"
url="data/jawiki-latest-pages-articles.xml"
transformer="RegexTransformer,DateFormatTransformer">
<field column="id" xpath="/mediawiki/page/id" />
<field column="title" xpath="/mediawiki/page/title" />
<field column="revision" xpath="/mediawiki/page/revision/id" />
<field column="user" xpath="/mediawiki/page/revision/contributor/username" />
<field column="userId" xpath="/mediawiki/page/revision/contributor/id" />
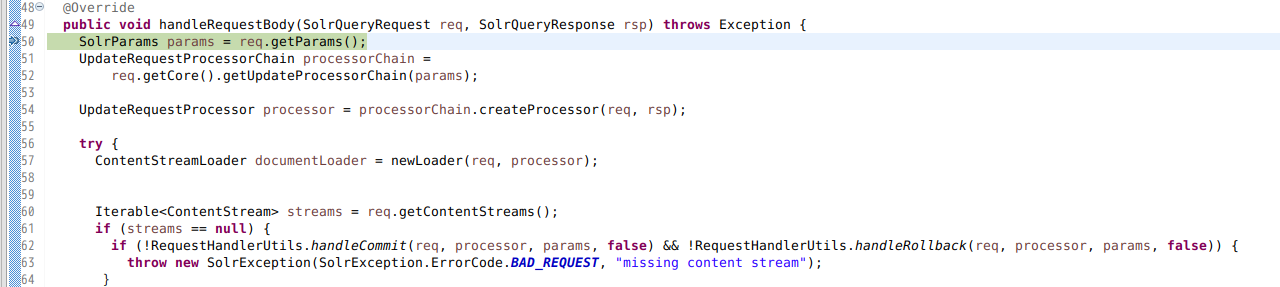
<field column="text" xpath="/mediawiki/page/revision/text" />
<field column="timestamp" xpath="/mediawiki/page/revision/timestamp" dateTimeFormat="yyyy-MM-dd'T'hh:mm:ss'Z'" />
<field column="$skipDoc" regex="^#REDIRECT .*" replaceWith="true" sourceColName="text"/>
</entity>
</document>
</dataConfig>configsetをアップロード
(cd server/solr/configsets/wikipedia/conf && zip -r - *) |curl -X POST --header "Content-Type:application/octet-stream" --data-binary @- "http://localhost:8983/solr/admin/configs?action=UPLOAD&name=wikipedia"コレクション”wikipedia”を作成
curl 'http://localhost:8983/solr/admin/collections?action=CREATE&name=wikipedia&numShards=1&replicationFactor=1&collection.configName=wikipedia&wt=xml'インポート開始
管理画面からインポート開始
各Tokenizerの設定
以下の4種類の設定で試してみます。
今回は手っ取り早く上記の手順の「configsetの準備」のところで managed-schema ファイルを編集しています。
CJK bigram
managed-schema の変更箇所
(略)
<pre>
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- normalize width before bigram, as e.g. half-width dakuten combine -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- for any non-CJK -->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.CJKBigramFilterFactory"/>
</analyzer>
</fieldType>
</pre>
(略)
<field name="title" type="string" indexed="true" stored="false"/>
<field name="revision" type="pint" indexed="true" stored="true"/>
<field name="user" type="string" indexed="true" stored="true"/>
<field name="userId" type="pint" indexed="true" stored="true"/>
<field name="text" type="text_cjk" indexed="true" stored="false"/>
<field name="timestamp" type="pdate" indexed="true" stored="true"/>
(略)Kuromoji (mode=normal)
辞書通りの分割
(例) 株式会社→「株式会社」
managed-schema の変更箇所
(略)
<pre>
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory" mode="normal"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt" />
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt" />
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</pre>
(略)
<field name="title" type="string" indexed="true" stored="false"/>
<field name="revision" type="pint" indexed="true" stored="true"/>
<field name="user" type="string" indexed="true" stored="true"/>
<field name="userId" type="pint" indexed="true" stored="true"/>
<field name="text" type="text_ja" indexed="true" stored="false"/>
<field name="timestamp" type="pdate" indexed="true" stored="true"/>
(略)Kuromoji (mode=search)
複合語を細かく分割
株式会社→「株式」「会社」
managed-schema の変更箇所
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>それ以外は mode=normal と同じ。
Kuromoji (mode=extended)
mode=search + 未知語を 1-gram に分割
managed-schema の変更箇所
<tokenizer class="solr.JapaneseTokenizerFactory" mode="extended"/>それ以外は mode=normal と同じ。
結果
| インデックスサイズ | 生成時間 | |
| CJK | 5.9GB | 35分 |
| Kuromoji(normal) | 3.1GB | 76分 |
| Kuromoji(search) | 3.1GB | 83分 |
| Kuromoji(extended) | 2.1GB | 79分 |
ちなみに、日本語版Wikipedia全記事のテキスト部分のサイズをカウントしてみたところ、約1.4GBでした。
まとめ
Solrで日本語版Wikipedia全記事のインデックスを作成しました。2-gramのインデックスサイズは形態素解析インデックスの約2倍になりました。
Kuromoji(extended)は未知語を1-gramに分割する分他のモードよりもインデックスサイズが大きくなると予想していたのですが、逆に30%強も小さくなりました。ここはもうちょっと調べてみる必要がありそうです。