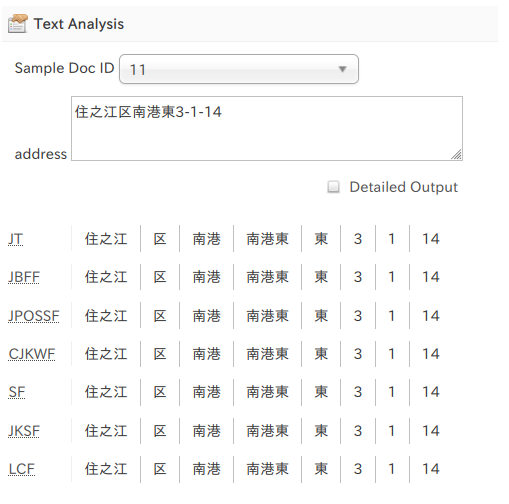
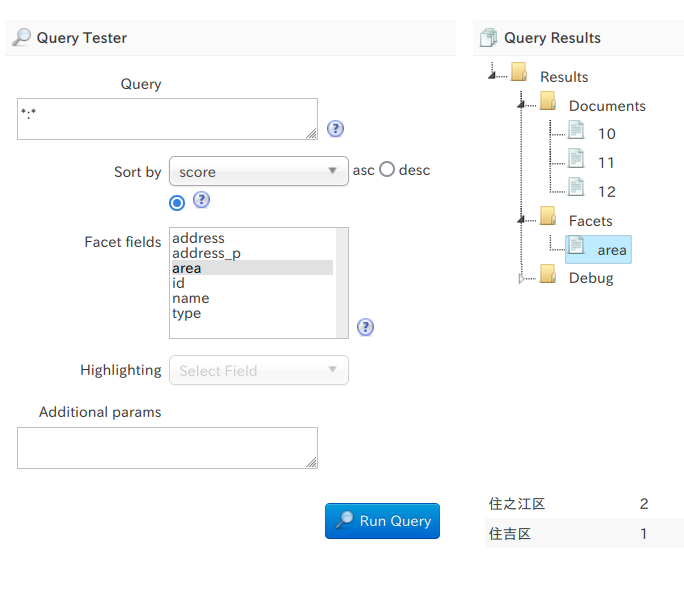
以前、グループ検索の手段として Result Grouping を紹介しました。
もう一つの手段として Collapse and Expand があります。 Collapse を辞書で引くと「つぶれる」とか「崩れる」とか出てきて少しイメージのしにくい言葉ですが、たとえばファイルビューアで言うと
↓これが Collapse している状態

↓これが Expand している状態
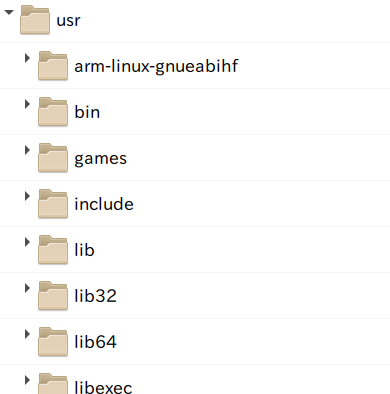
と捉えると分かりやすいかと思います。
Solr における検索結果の Collapse とは特定のフィールドの値に基づいて検索結果をグループ分けし、各グループの代表ドキュメントを出力することであり、Expand とは Collapse で作られた各グループに属するドキュメントを選択して出力することです。
Collapsing は CollapsingQParser で実装されており、フィルタクエリで指定します。以下は大阪の施設情報を施設タイプ(typeフィールド)でグルーピングするクエリ例です。
$ curl http://localhost:8983/solr/osaka_shisetsu/select -d 'q=*:*&rows=3&omitHeader=true&fq={!collapse field=type}'
{
"response":{"numFound":13,"start":0,"numFoundExact":true,"docs":[
{
"id":"10",
"type":"官公庁",
"area":"住之江区",
"name":"軽自動車検査協会大阪主管事務所",
"address":["住之江区南港東3-4-62"],
"address_p":"34.6164938333333,135.438210722222",
"_version_":1695487381634809856},
{
"id":"311",
"type":"学校・保育所",
"area":"住之江区",
"name":"大和幼稚園",
"address":["大阪市住之江区北島3-3-11"],
"address_p":"34.6013536388888,135.478355305555",
"_version_":1695487381872836611},
{
"id":"1356",
"type":"公園・スポーツ",
"area":"住之江区",
"name":"住之江公園プール",
"address":["住之江区南加賀屋1住之江公園内"],
"address_p":"34.6118221111111,135.473814305555",
"_version_":1695487382023831552}]
}}
各グループ5件ずつのドキュメントが欲しい、といった場合には expand=true を指定します。以下は、typeフィールドでグループ化して、各グループ2件ずつのドキュメントを取得するクエリ例です。
$ curl --user solr:SolrRocks http://localhost:8983/solr/osaka_shisetsu/select -d 'q=*:*&rows=3&omitHeader=true&fq={!collapse field=type}&expand=true&expand.rows=2'
{
"response":{"numFound":13,"start":0,"numFoundExact":true,"docs":[
{
"id":"10",
"type":"官公庁",
"area":"住之江区",
"name":"軽自動車検査協会大阪主管事務所",
"address":["住之江区南港東3-4-62"],
"address_p":"34.6164938333333,135.438210722222",
"_version_":1695487381634809856},
{
"id":"311",
"type":"学校・保育所",
"area":"住之江区",
"name":"大和幼稚園",
"address":["大阪市住之江区北島3-3-11"],
"address_p":"34.6013536388888,135.478355305555",
"_version_":1695487381872836611},
{
"id":"1356",
"type":"公園・スポーツ",
"area":"住之江区",
"name":"住之江公園プール",
"address":["住之江区南加賀屋1住之江公園内"],
"address_p":"34.6118221111111,135.473814305555",
"_version_":1695487382023831552}]
},
"expanded":{
"公園・スポーツ":{"numFound":1089,"start":0,"numFoundExact":true,"docs":[
{
"id":"1357",
"type":"公園・スポーツ",
"area":"住之江区",
"name":"住之江公園野球場",
"address":["住之江区南加賀屋1住之江公園内"],
"address_p":"34.6116668611111,135.475586222222",
"_version_":1695487382023831553},
{
"id":"1358",
"type":"公園・スポーツ",
"area":"住之江区",
"name":"住之江公園多目的広場",
"address":["住之江区南加賀屋1住之江公園内"],
"address_p":"34.6105608055555,135.475235888888",
"_version_":1695487382023831554}]
},
"学校・保育所":{"numFound":1044,"start":0,"numFoundExact":true,"docs":[
{
"id":"312",
"type":"学校・保育所",
"area":"住吉区",
"name":"大阪市立墨江幼稚園",
"address":["住吉区墨江2丁目3番17号"],
"address_p":"34.6077390555555,135.496024694444",
"_version_":1695487381872836612},
{
"id":"313",
"type":"学校・保育所",
"area":"住之江区",
"name":"加賀幼稚園",
"address":["大阪市住之江区中加賀屋4-4-22"],
"address_p":"34.6140463611111,135.478756833333",
"_version_":1695487381872836613}]
},
"官公庁":{"numFound":300,"start":0,"numFoundExact":true,"docs":[
{
"id":"11",
"type":"官公庁",
"area":"住之江区",
"name":"大阪陸運支局なにわ自動車検査登録事務所",
"address":["住之江区南港東3-1-14"],
"address_p":"34.6190439722222,135.442191833333",
"_version_":1695487381820407808},
{
"id":"12",
"type":"官公庁",
"area":"住吉区",
"name":"住吉税務署",
"address":["住吉区住吉2丁目17番37号"],
"address_p":"34.6109641111111,135.491388722222",
"_version_":1695487381821456384}]
}}}
この結果を使えば、まさに先程ファイルビューアの例で示したような検索結果の表示が実現できることが分かります。