SolrのUAX29URLEmailTokenizerを使う
Solrにはさまざまなトークナイザーが用意されており、その中に UAX29URLEmailTokenizer があります。
このトークナイザーは基本的には StandardTokenizer と同じ挙動なのですが、以下の要素をトークンとして切り出してくれるという特徴があります。
- ドメイン名
- URL(http(s)://, file://, ftp://)
- Eメールアドレス
- IPアドレス(IPv4とIPv6)
UAX29URLEmailTokenizer を使うフィールドタイプとフィールドを定義して動作を確認してみます。
<fieldType name="text_url" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.UAX29URLEmailTokenizerFactory"/>
</analyzer>
</fieldType>
<field name="url_test" type="text_url" stored="true"/>
この設定で「http://www.example.com/example/です。」をトークナイズした結果は以下の通りです。
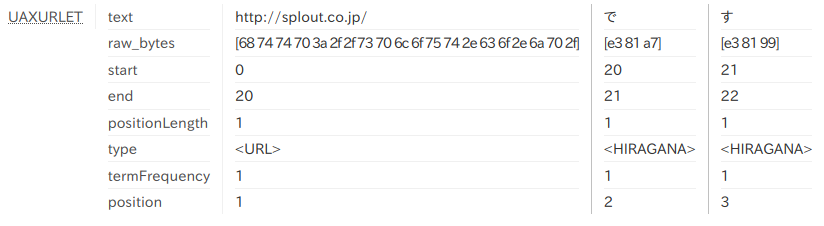
日本語の文書を扱う場合、通常の文章の部分が StandardTokenizer 相当でトークナイズされるといろいろ使い勝手が悪いので、たとえば形態素解析のトークナイザーと組み合わせることを考えます。
<fieldType name="url" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.UAX29URLEmailTokenizerFactory"/>
<filter class="solr.TypeTokenFilterFactory" types="url_whitelist.txt" useWhitelist="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
</fieldType>
<field name="body" type="text_ja" stored="true"/>
<field name="url" type="url" stored="true"/>
<copyField source="body" dest="url"/>
UAX29URLEmailTokenizer の後ろに TypeTokenFilter を追加することで、必要なトークンタイプだけを残すことができます。TypeTokenFilter のホワイトリストとして url_whitelist.txt に以下の1行だけを記述して、URLだけを残すようにします。
<URL>
クエリ用のアナライザを別に定義したのは、URLのフィールドの検索では余計なトークナイズをさせずに文字列マッチ相当の動作にしたいからです。
urlフィールドをurlフィールドタイプとして定義し、text_jaフィールドタイプであるbodyフィールドのコピーフィールドにしています。
以下の文書を投入します。
[
{"id":"1",
"body":"昨日 http://blog.splout.co.jp/ をみた。"
},
{"id":"2",
"body":"明後日は http://splout.co.jp/ をみる。"
}
]
各フィールドにどういうトークンが納められたのかを確認します。
$ curl -s 'http://localhost:8983/solr/urlTokenizer/terms?terms.fl=url&terms.limit=-1&omitHeader=true&wt=json'
{
"terms":{
"url":[
"http://blog.splout.co.jp/",1,
"http://splout.co.jp/",1]}}
urlフィールドにはURLだけが納められています。
$ curl -s 'http://localhost:8983/solr/urlTokenizer/terms?terms.fl=body&terms.limit=-1&omitHeader=true&wt=json'
{
"terms":{
"body":[
"co",2,
"http",2,
"jp",2,
"splout",2,
"みる",2,
"blog",1,
"明後日",1,
"昨日",1]}}
bodyフィールドには通常の形態素解析結果が納められています。
この状態で検索してみます。まずは body フィールドを “http://splout.co.jp/” で。
$ curl -s 'http://localhost:8983/solr/urlTokenizer/select?q=body%3Ahttp%5C%3A%5C%2F%5C%2Fsplout.co.jp%5C%2F'
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"body:http\\:\\/\\/splout.co.jp\\/"}},
"response":{"numFound":2,"start":0,"docs":[
{
"id":"2",
"body":"明後日は http://splout.co.jp/ をみる。",
"url":"明後日は http://splout.co.jp/ をみる。",
"_version_":1656715432355168256},
{
"id":"1",
"body":"昨日 http://blog.splout.co.jp/ をみた。",
"url":"昨日 http://blog.splout.co.jp/ をみた。",
"_version_":1656715432353071104}]
}}
“http”, “splout”, “co”, “jp” がバラバラにトークンとして扱われるので、”http://blog.splout.co.jp/” も “http://splout.co.jp/” も両方がヒットしています。
次に url フィールドを同じく “http://splout.co.jp/” で。
$ curl -s 'http://localhost:8983/solr/urlTokenizer/select?q=url%3Ahttp%5C%3A%5C%2F%5C%2Fsplout.co.jp%5C%2F'
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"url:http\\:\\/\\/splout.co.jp\\/"}},
"response":{"numFound":1,"start":0,"docs":[
{
"id":"2",
"body":"明後日は http://splout.co.jp/ をみる。",
"url":"明後日は http://splout.co.jp/ をみる。",
"_version_":1656715432355168256}]
}}
“http://splout.co.jp/” の方だけがヒットします。
urlフィールドの検索ではワイルドカードを使うこともできます。”http://*.splout.co.jp/” を指定して splout.co.jp のサブドメインだけを検索してみます。
$ curl -s 'http://localhost:8983/solr/urlTokenizer/select?q=url%3Ahttp%5C%3A%5C%2F%5C%2F*.splout.co.jp%5C%2F'
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":1,
"params":{
"q":"url:http\\:\\/\\/*.splout.co.jp\\/"}},
"response":{"numFound":1,"start":0,"docs":[
{
"id":"1",
"body":"昨日 http://blog.splout.co.jp/ をみた。",
"url":"昨日 http://blog.splout.co.jp/ をみた。",
"_version_":1656715432353071104}]
}}
文章に含まれるURLやメールアドレスの扱いは案外面倒なものです。
UAX29URLEmailTokenizer をうまく使えば、自前でURLやメールアドレスを抽出してstringフィールドに格納するよりもバグも少なく取り扱うことができるでしょう。