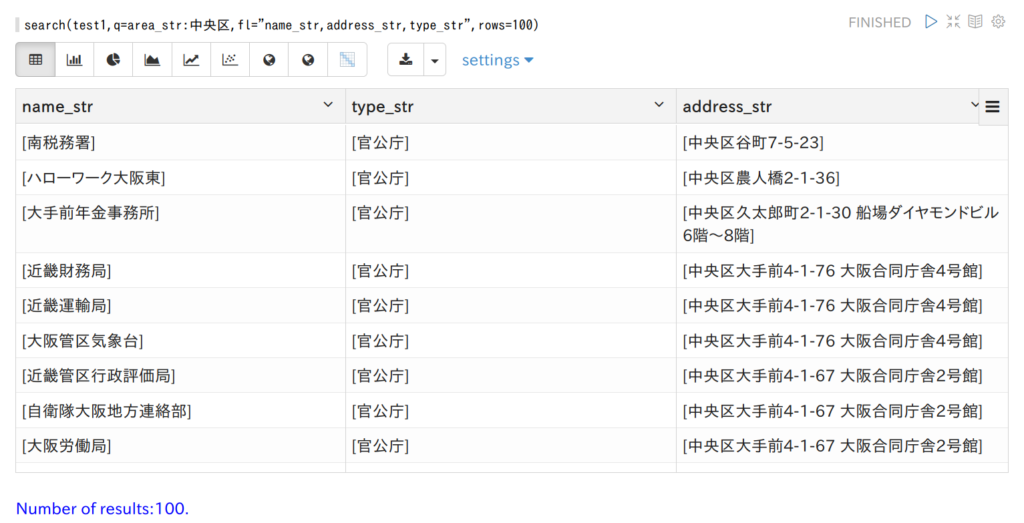
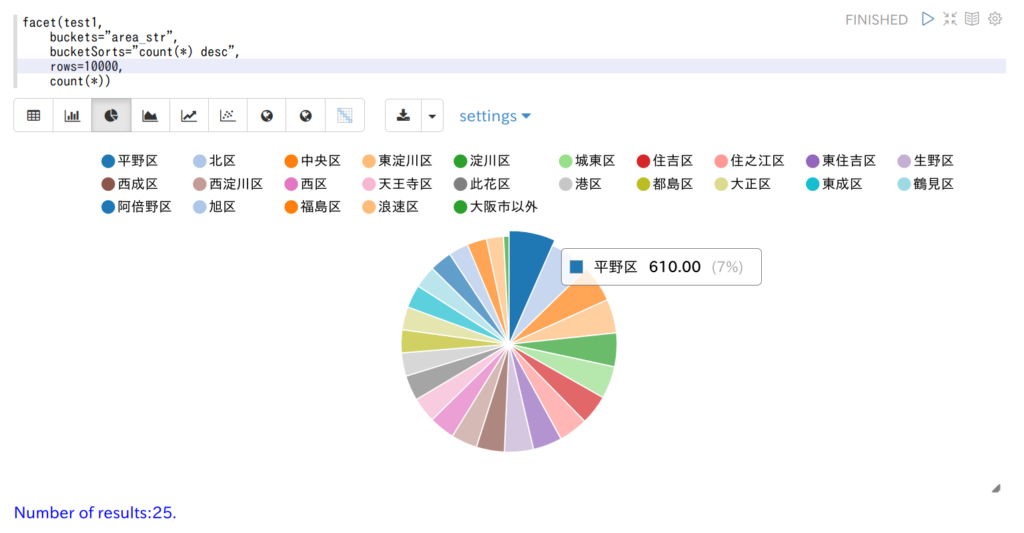
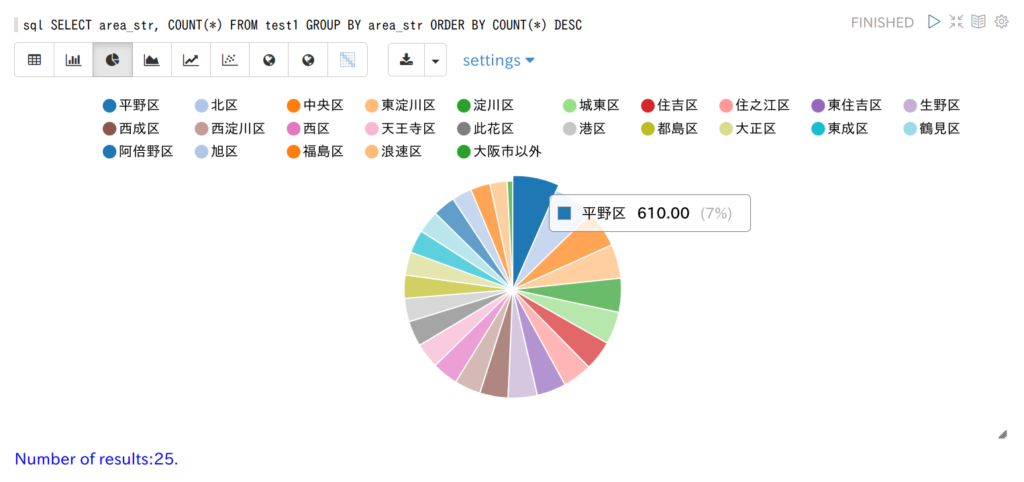
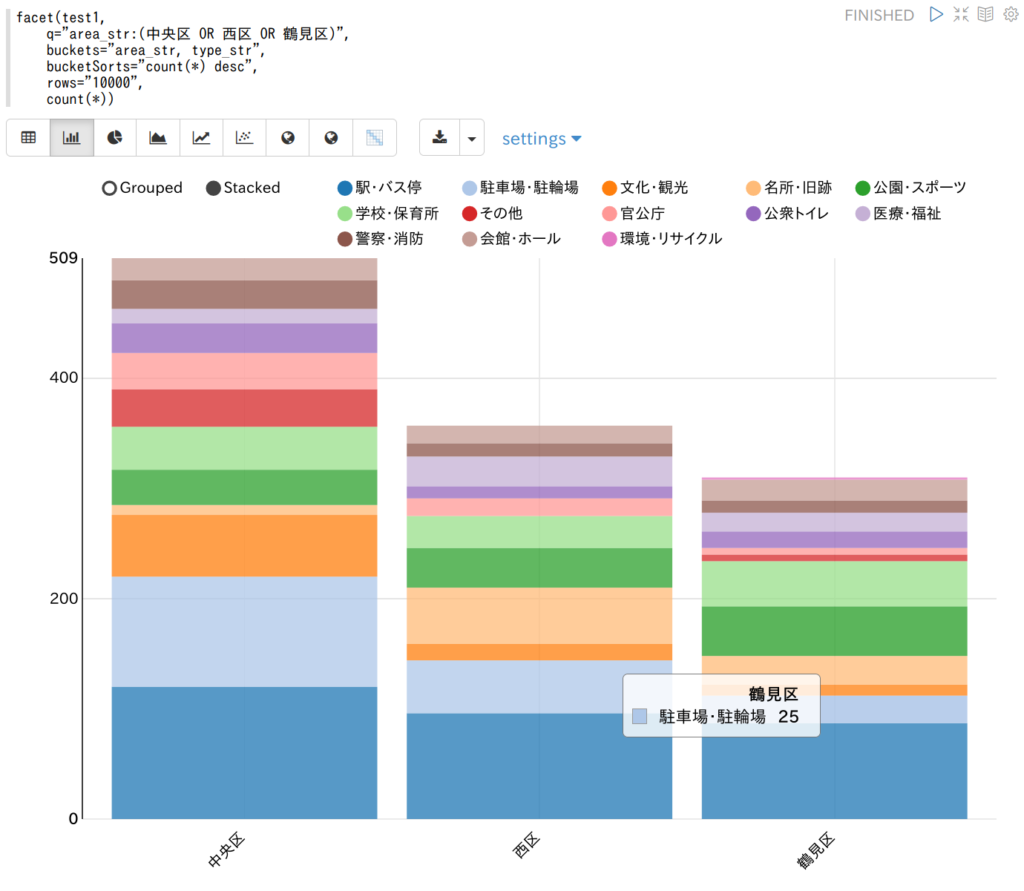
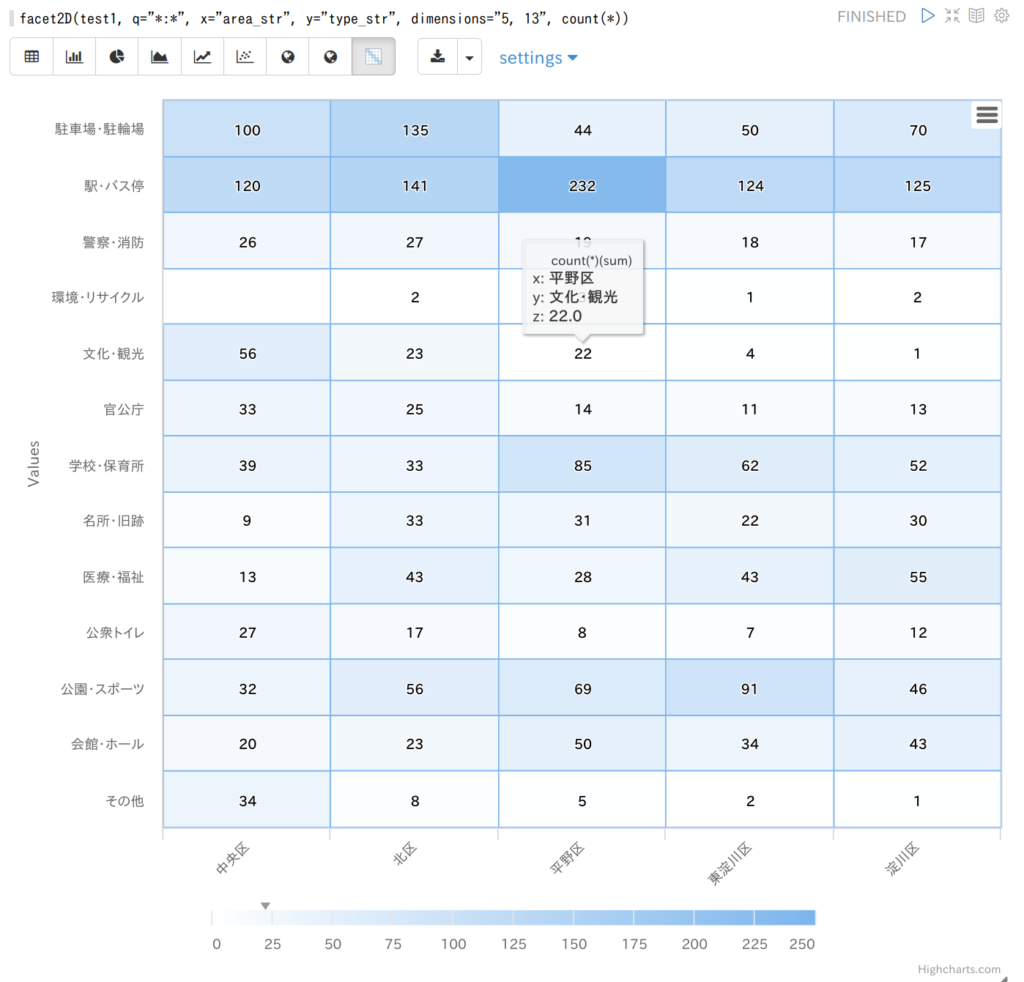
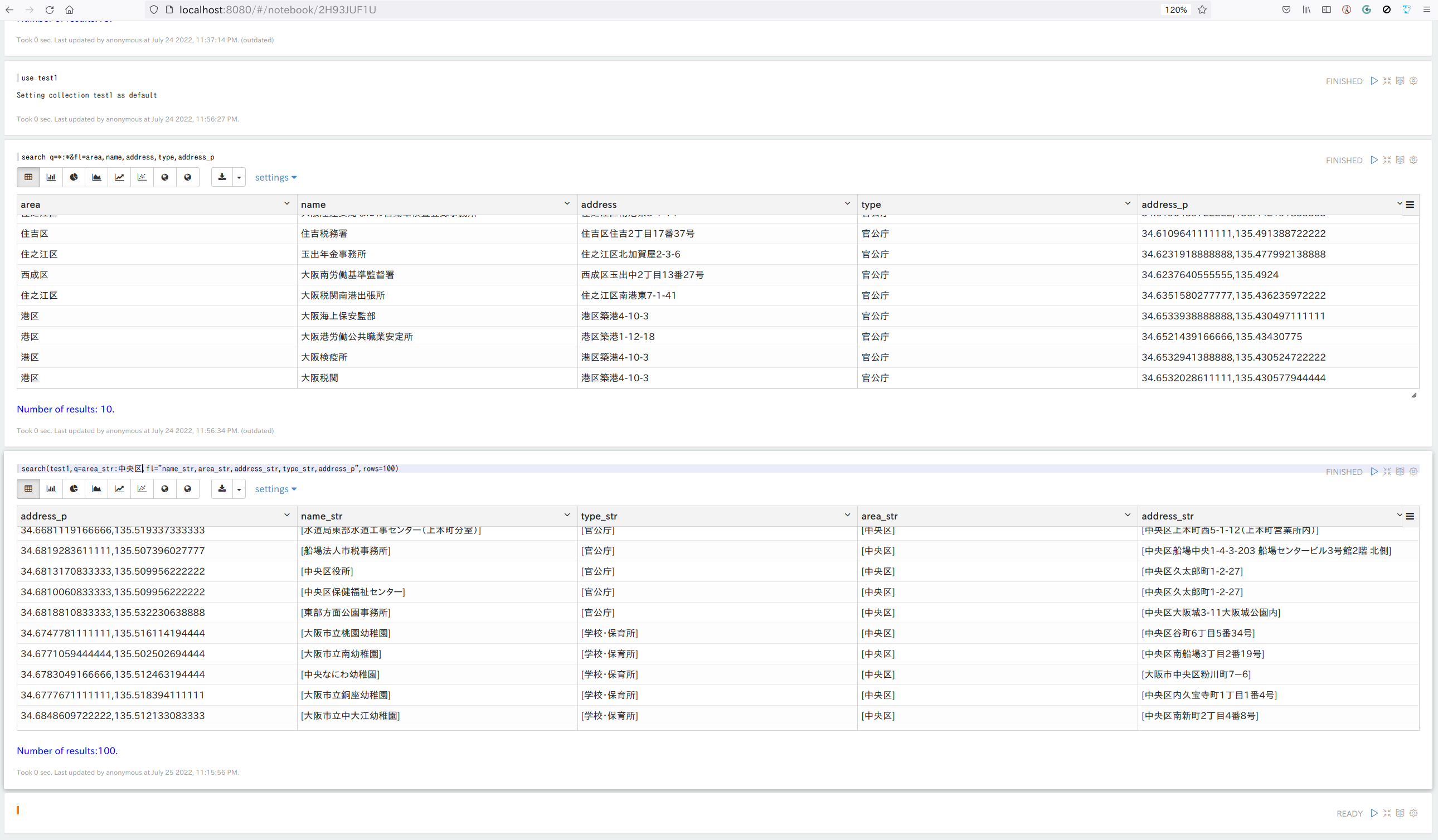
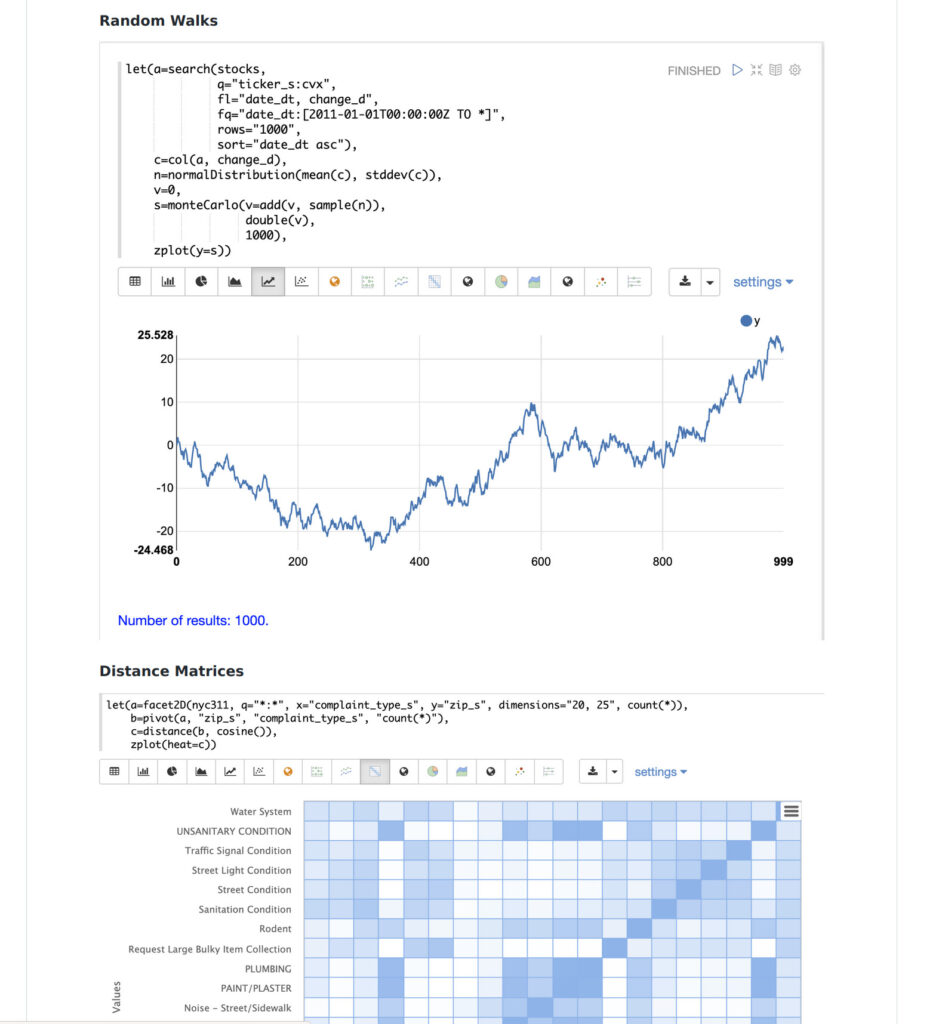
SQSのFIFOキューと標準キューの大まかな違い
前に勘違いして使っていたことがあったので書きます。結論だけ先に書いてあとは蛇足になります。
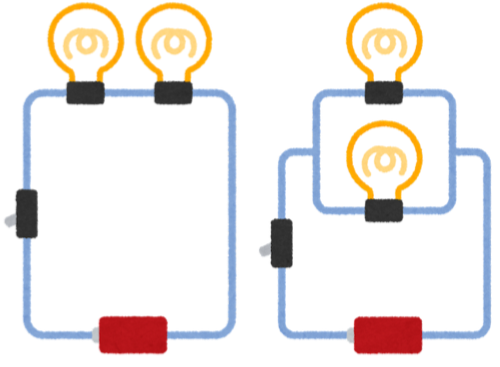
・FIFOキューは直列、標準キューは並列といったイメージ
気を付けておくこととして
・FIFOキューはメッセージ毎の遅延が利用できない
・標準キューは2回以上配信される可能性がある
大半は標準キューを利用してどうしても1つずつ実行される必要があるようなものはFIFOを使うといったぐらいの認識でいい気がします。
以下は蛇足分になります。
気づいたのは処理が多くなってきたので実行数を増やしたが実行ログを見る限りだと完全に終わってから実行されているような・・・といったことからわかりました。増やす必要ができたもの以外は1回だけ配信されて欲しい内容が大半で基本的にFIFOのままで問題なかったのですが、増やそうとしている処理は複数実行されていかないと処理しきれないので将来的にキューが溜まり続ける未来が容易に予想でき、また標準キューにしていなかった理由も内部では実行時のチェックはやっているので1回だけの必要があるというわけではなく単純に他が全部FIFOだったからそのままFIFOでやってしまったというだけだったので原因がわかればそう難しいことではなかったのですがイメージ的に順番が保証されてるかされていないかと一回切りか複数回の可能性があるかぐらいの認識だったのでそこの部分を誤認識していたという話です。