Visual Studio Codeのユーザースニペットの使い方

Visual Studio Code(VS Code) を使う上で便利な機能の一つに「ユーザースニペット」というものがあります。
コードを書く上で同じ内容を書くことがよくあると思います。
よく使うコードは「ユーザースニペット」に登録しておくとコーディングが楽になります。
「ユーザースニペット」とは、コードをあらかじめスニペットに登録することでコードを簡単に呼び出せる機能です。
VS Codeの「基本設定」をクリックします。
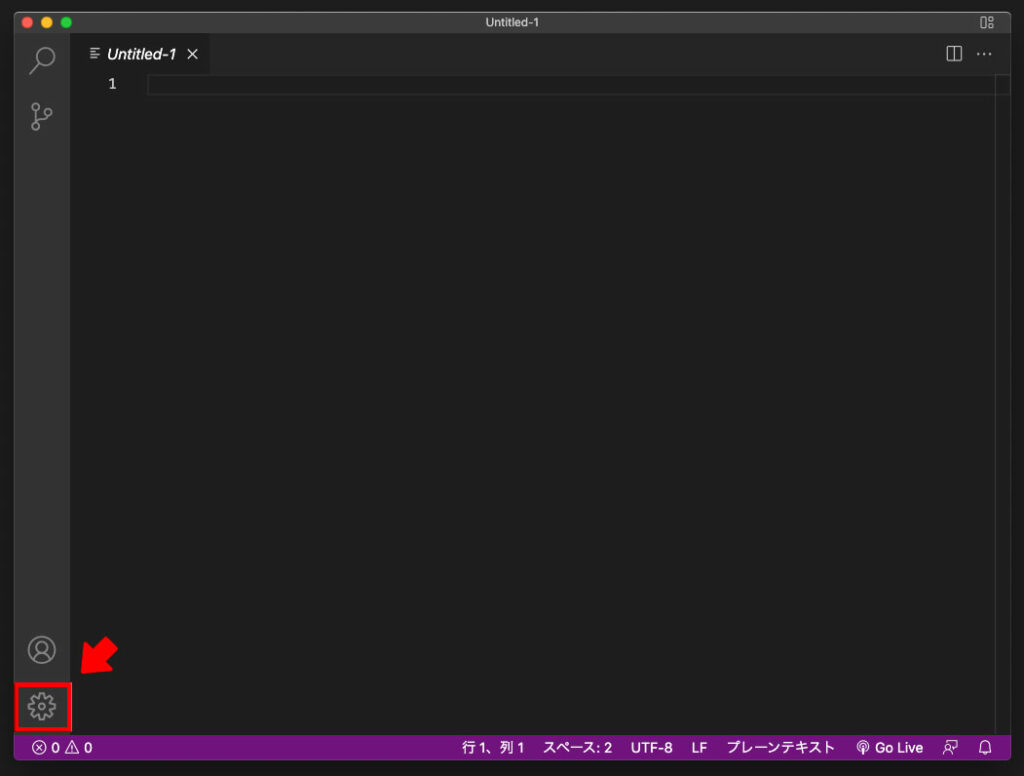
ユーザースニペットを開きます。
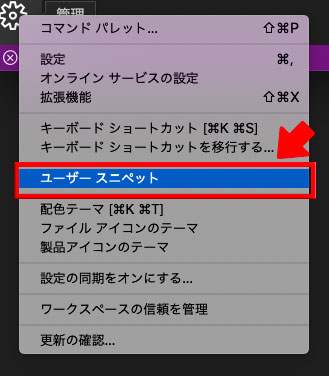
「css、scss」両方に適応させたいなど、複数ファイルに適応させたいの場合は、「新しいグローバルスニペットファイル」を選択します。
(ここでは「新しいグローバルスニペットファイル」の方法を紹介しますが、特定の拡張子を選択した場合も同様です。)
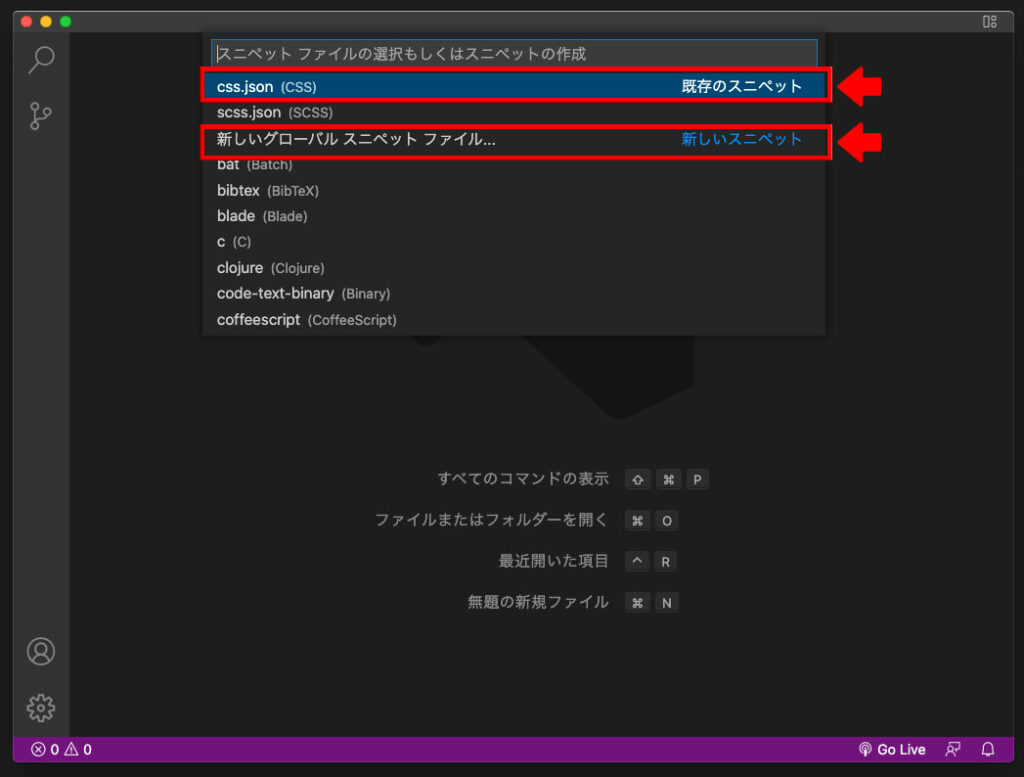
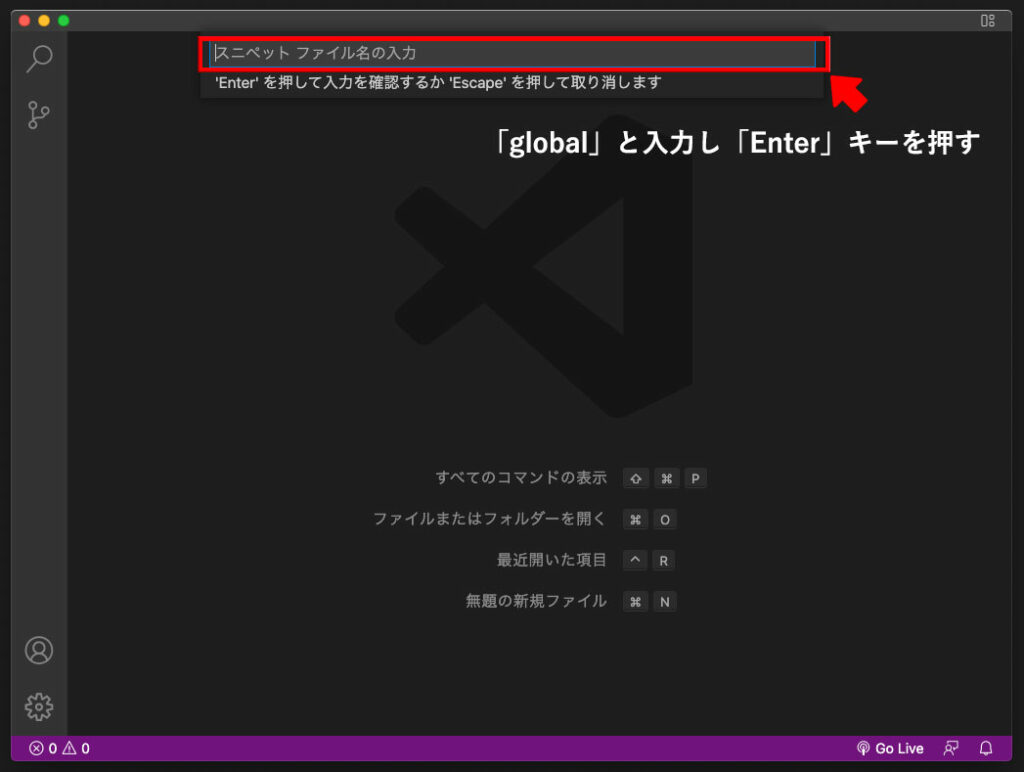
ファイル名の入力を求められるので、わかりやすい名前を入力します。
今回は「global」と入力し「Enter」を押しました。
そうすると新しく「global.code-snippets」というファイルができるのでそこにスニペットを登録していきます。サンプルとして下記のような内容を登録します。
{
"bg": { // スニペット名
"scope": "css,scss", // 対象言語
"prefix": "+bg", // スニペットを呼び出すための単語
"body": [
"background: url('') transparent top left / auto auto no-repeat;", // 出力内容
]
},
}
保存後に、cssまたはscssファイルを開き、「+bg」と入力すると、候補が現れ、選択すると登録内容が出力されます。
複数登録する場合は下記のように続けます。
{
"bg": {
"scope": "css,scss",
"prefix": "+bg",
"body": [
"background: url('') transparent top left / auto auto no-repeat;",
]
},
"@media": {
"scope": "css,scss",
"prefix": "+@media",
"body": [
"@media screen and (max-width: 900px){}",
]
},
}下記のようにbodyの中に「$1」「$2」と書くと初期のカーソル位置を設定できます。
Tabキーを押すことで「$1」→「$2」の順に移動します。
${1:900}のように書くことであらかじめ、値を入力することもできます。
{
"bg": {
"scope": "css,scss",
"prefix": "+bg",
"body": [
"background: url('$1') transparent top left / auto auto no-repeat;",
]
},
"@media": {
"scope": "css,scss",
"prefix": "+@media",
"body": [
"@media screen and (max-width: ${1:900}px){$2}",
]
},
}今回はVS codeのスニペット機能について紹介しました。
コーディングの効率化の参考になれば幸いです!

