「RubyWorld Conference 2022」に協賛させていただきます

「RubyWorld Conference 2022」に、Goldスポンサーとして協賛させていただきます。
<期間>
2022年11月10日(木)・11日(金)
<会場>
島根県立産業交流会館「くにびきメッセ」
<主催>
RubyWorld Conference開催実行委員会
https://2022.rubyworld-conf.org/ja/
「RubyWorld Conference 2022」に、Goldスポンサーとして協賛させていただきます。
<期間>
2022年11月10日(木)・11日(金)
<会場>
島根県立産業交流会館「くにびきメッセ」
<主催>
RubyWorld Conference開催実行委員会
https://2022.rubyworld-conf.org/ja/
わたしの部屋には、植物とときどき、いや、ほぼ毎日花を飾っています。
まめな性格ではないわたしが、植物ましてや、生花を楽しむことなんてできないとずっと思っていました。枯らしてしまう未来しか想像ができなかったのです。
そんなわたしが、花を愛でるきっかけになった日のことを思い出してみました。
(最後にはおすすめの植物も紹介しちゃうよ)
ドラマでもないようなハプニングが多発して、可笑しくて涙がぼろぼろ溢れてきたそんな日でした。
家までの帰り道にある花屋に、「売れ残り3本で100円」の芍薬が並んでいました。
その花に親近感が湧いて、売れ残りの名前すら知らなかったその花を買って、家にある空のペットボトルに水を入れて飾りました。
次の日、朝起きて昨日買った芍薬をふと見ると蕾だった花が、綺麗に咲いていて、ちょっとだけうれしい気持ちになりました。
いま、自分に「好きな花はなに?」と聞かれても、答えれないのはなんだか嫌だなと思って、そこから花に興味を持ち始めました。
花だけではなく、植物にも同じように興味が出てきて、今では植物を毎日、愛でまくっています。
話しかけてみたり、いろんな場所に置いてみたり、みるみるうちに、どんどん大きくなっていて、成長を観察することが楽しみになっています。
友人にどの植物がおすすめ?と聞かれたら、迷わず答えるのが、エバーフレッシュです。夜になると葉っぱが閉じて二度楽しめます。
お迎えした時のエバーフレッシュ↓

現在のエバーフレッシュ↓

水やりのタイミングが難しいと思うのですが、私は葉っぱが元気ないな?と思ったらたっぷりのお水をやる。
それくらいの心持ちでここまでぐんぐん大きくなりました。
また猫にも大丈夫な植物でもあるのです。
緑のある暮らしは、フルリモートである人にはぜひおすすめしたいです。
bin/solr スクリプトは意外と多機能です。
Solrリファレンスの該当箇所を抄訳してみました。
bin/solr start [options]
bin/solr restart [options]
-a “<string>”
JVMパラメータを指定する
-cloud (-c)
SolrCloud モードで起動
-d <dir>
サーバディレクトリを指定する(デフォルト: $SOLR_HOME/server)
-f
フォアグラウンドで起動する
-h <hostname>
ホスト名を指定して起動する。指定しない場合は ‘localhost’
-m memory
ヒープサイズを指定する
-noprompt
例えば -e オプションを指定したときなど、起動時のプロンプトを抑制してデフォルト値を指定したことにする。
-p <port>
ポートを指定する。省略した場合は ‘8983’
-s <dir>
システムプロパティ solr.solr.home を設定する。
-v
Solrのログ出力を増やす。ログレベルがINFOからDEBUGに変更される。
-q
Solrのログ出力を抑制する。ログレベルがINFOからWARNに変更される。
-V
起動スクリプトのログ出力を増やす。
-z <zkHost>
ZooKeeper 用の接続文字列を定義する。
-force
rootユーザで強制的に起動する場合に指定する。
bin/solr start -e
cloud
同じマシン上で動く複数のノードを使ったSolrCloudクラスタを起動する
techproducts
$SOLR_HOME/example/exampledocs にあるサンプルドキュメントに合わせたスキーマを使ってスタンドアローンモードで起動する
dih
DataImportHandlerの仕様例をスタンドアローンモードで起動する
schemaless
スキーマレスモードの例をスタンドアローンモードで起動する
bin/solr stop [options]
-p <port>
停止するSolrプロセスを、利用しているポート番号で指定する。
-all
稼働中のSolrプロセスをすべて停止する。
-k <key>
間違えて停止しないように、キーを指定する。
(起動時に -DSTOP.KEY で設定したキーを指定する)
bin/solr version
Solr のバージョンを表示する
bin/solr status
稼働中の Solr インスタンスの状態を表示する
bin/solr assert
Solr のインストール状態について調べる。
-c, –cloud <url>
-C, –not-cloud <url>
Solr が cloud モードで動作しているかどうか
-e, –exitcode <exitcode>
エラーの場合に指定した exitcode で終了する
-m, –message <message>
エラーの場合に指定したメッセージを出力する
-R, –not-root
-r, –root
このユーザがrootかどうか
-S, –not-started <url>
-s, –started <url>
Solr が指定されたURLで稼働中かどうか
-t, –timeout <ms>
指定した時間内にタイムアウトするかどうか
-u, –same-user <directory>
このユーザと指定したディレクトリの所有者が同じかどうか
-x, –exists <directory>
-X, –not-exists <directory>
指定したディレクトリが存在するかどうか
bin/solr healthcheck [options]
Solr の稼働状態をレポートする
-c
コレクション名
-z
ZooKeeperの接続先
bin/solr create [options]
コレクションやコアの生成
-c <name>
コレクション・コア名
-d <confdir>
設定のあるディレクトリ
-n <configName>
設定名
-p <port>
Solr のポート番号
-s , -shards <shards>
シャード数
-rf , -replicationFactor <replicas>
コレクション内のレプリカ数
-force
rootユーザによる実行(通常は何もせず警告を出して終了する)を強行する
bin/solr delete [options]
コレクションやコアの削除
-c <name>
コレクション・コア名
-deleteConfig
同時に ZooKeeper から設定も削除する
-p
Solr のポート番号
bin/solr auth enable
BASIC認証を有効にする
-credentials
username:password の形式でユーザとパスワードを指定
-prompt
プロンプトを表示してユーザとパスワードを入力する場合に true を指定
-blockUnknown
true を指定すると、未認証のユーザからのすべてのアクセスをブロックする
-z
ZooKeeper の接続先
-d
Solr のサーバディレクトリ
-s
solr.solr.home の場所(デフォルトは server/solr)
bin/solr auth disable
BASIC認証を無効にする
bin/solr export [options]
コレクション内のドキュメントをエクスポートする
-url <url>
対象とするコレクションのURL
format
出力フォーマット(jsonl(デフォルト),javabin)
out
出力ファイル名
query
出力対象を指定するクエリ(デフォルト:)
fields
出力対象のフィールド名(カンマ区切り)
limit
出力する件数

「Google Chrome 97」のオリジントライアルに追加されたWebTransportを早速触ってみたいと思います。
WebTransport is a protocol framework that enables clients constrained by the Web security model to communicate with a remote server using a secure multiplexed transport.
https://chromestatus.com/feature/4854144902889472
WebTransportは、HTTP/3プロトコルを双方向トランスポートとして使用するWebAPIです。これは、WebクライアントとHTTP/3サーバー間の双方向通信を目的としています。データグラムAPIを介した信頼性の低いデータ送信と、ストリームAPIを介した信頼性の高いデータ送信の両方をサポートします。
https://web.dev/webtransport/
なんだかよく分かりませんが、HTTP/3を使用したすごい転送規格です。
双方向ですし、multiplexed-transport?かっこいいですね。
きっとブラウザOSが更に進化していくとか、ブラウザ上でゲームがネイティブアプリかのように動作するだとか、もうブラウザの意味が変わる時代が来るのかもしれません。
内容自体は難解かつ複雑ですが、今回はサンプルを触るだけですので何も考えずにやってみようと思います。
「WebTransportの実験」によると、現時点では、WebTransportはまだ公開されていません。
「試してみましょう」の項目にもありますが、HTTP/3サーバーをローカルで準備して起動する必要があるとのこと。
JavaScriptクライアントは、以下のURLに用意してくれています。
https://googlechrome.github.io/samples/webtransport/client.html
HTTP/3サーバーとは?
となったところで、GoogleChrome/samplesのgithubのスクリプトの中にコメントで、
An example WebTransport over HTTP/3 server based on the aioquic library. とありました。
aioquicを検索してみるとすぐ出てきたので、githubからcloneしてきます。
https://github.com/aiortc/aioquic/
導入は README の通りに進めます。
親切なことに、ブラウザの起動方法やオプションの説明、test/ ディレクトリの下に .pem ファイルまで用意されています。(独自証明書の場合のハッシュの生成コマンドもあります。)
Chromeもこれぐらいやって欲しい
また、aioquic/exapmplesにHTTP/3のテスト用サンプルが置いてあります。
試してみたところ、サーバー起動とHTTP/3のサンプルスクリプトは動作したのですが、クライアントからWebTransportの接続が上手くいきませんでした。深追いはしてませんが、バージョンアップで何か変わったのかもしれません。
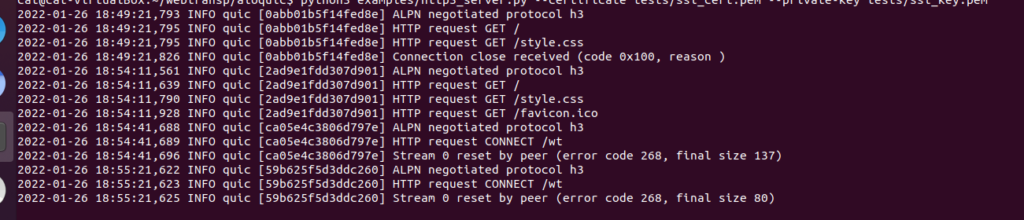
ということで、元のGoogleChrome/samplesに戻ります。
cloneしてきたGoogleChome/samplesからサーバー用スクリプトを起動します。
mv samples/webtransport/webtransport_server.py aioquic/
python3 webtransport_server.py tests/ssl_cert.pem tests/ssl_key.pem aioquicの説明の通り、Chromiumをコマンドから起動します。
chromium --enable-experimental-web-platform-features --ignore-certificate-errors-spki-list=BSQJ0jkQ7wwhR7KvPZ+DSNk2XTZ/ MS6xCbo9qu++VdQ= --origin-to-force-quic-on=localhost:4433 https://localhost:4433/ 上の方で紹介したJavaScriptクライアントを開きます。
https://googlechrome.github.io/samples/webtransport/client.html
画面にある「Connect」を押し、以下のように表示されると接続成功です。
Initiating connection...
Connection ready.
Datagram writer ready.
Datagram reader ready.お疲れさまでした。
Solrの管理画面 Logging → Level で Solr 稼働中にログレベルを変更できます。
特定のクラスのログ出力だけを変更することもできますし、rootを変更することで全体を変更することもできます。
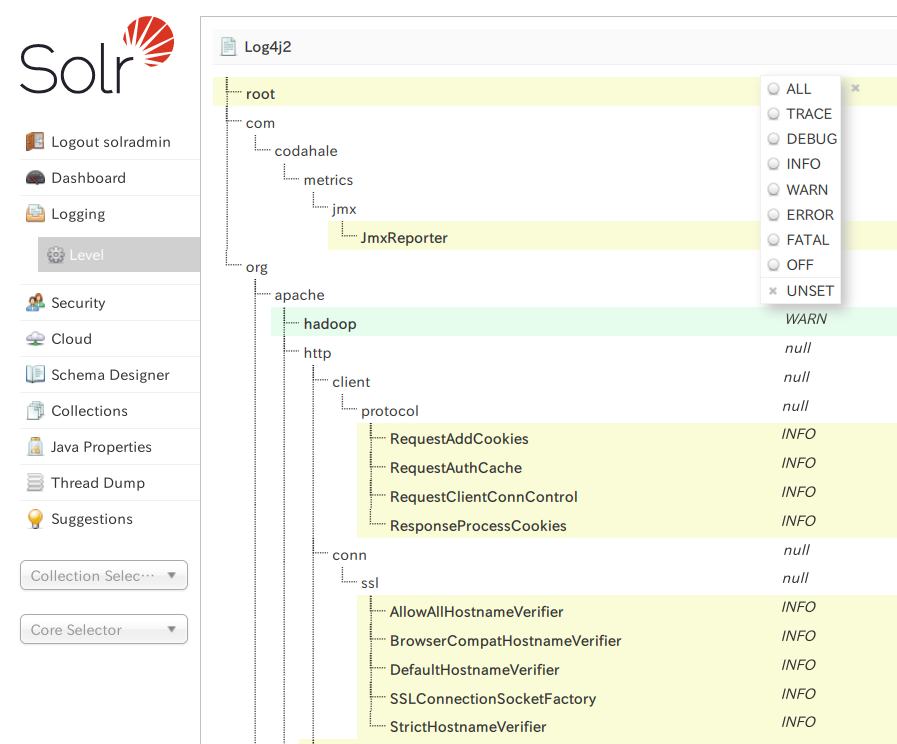
以下のようにAPIを呼び出すことでログレベルを変更できます。
curl -s http://localhost:8983/solr/admin/info/logging --data-binary "set=root:WARN"
環境変数 LOG4J_PROPS で log4j2.xml の場所を指定します。
LOG4J_PROPS=/var/solr/log4j2.xml
環境変数 SOLR_LOGS_DIR でログの出力先を指定します。
SOLR_LOGS_DIR=/var/solr/logs
log4j2.xml の MailLogFile の設定を以下のように変更します。
<RollingRandomAccessFile
name="MainLogFile"
fileName="${sys:solr.log.dir}/solr.log"
filePattern="${sys:solr.log.dir}/solr.log.%d{yyyyMMdd}" >
<PatternLayout>
<Pattern>
%maxLen{%d{yyyy-MM-dd HH:mm:ss.SSS} %-5p (%t) [%X{collection} %X{shard} %X{replica} %X{core}] %c{1.} %m%notEmpty{\
=>%ex{short}}}{10240}%n
</Pattern>
</PatternLayout>
<Policies>
<TimeBasedTriggeringPolicy interval="1"/>
</Policies>
<DefaultRolloverStrategy max="10"/>
</RollingRandomAccessFile>
TimeBasedTriggeringPolicy の interval=1 が1日単位という意味になるのは、filePattern に含まれる最小の単位が日だからです。filePattern に HH が含まれていれば interval=1 は1時間単位の意味になり、 mm が含まれていれば1分単位になります。
Solr の配布物に含まれる log4j2 関連の jar ファイルは以下の通りです。
log4j2 をアップデートするときはこれらのファイルを置き換えます。
prometheus-exporter を利用している場合は以下のファイルの置き換えも必要です。