WebTransportのサンプルを触ってみる。

「Google Chrome 97」のオリジントライアルに追加されたWebTransportを早速触ってみたいと思います。
WebTransportとは・・・。
WebTransport is a protocol framework that enables clients constrained by the Web security model to communicate with a remote server using a secure multiplexed transport.
https://chromestatus.com/feature/4854144902889472
WebTransportは、HTTP/3プロトコルを双方向トランスポートとして使用するWebAPIです。これは、WebクライアントとHTTP/3サーバー間の双方向通信を目的としています。データグラムAPIを介した信頼性の低いデータ送信と、ストリームAPIを介した信頼性の高いデータ送信の両方をサポートします。
https://web.dev/webtransport/
なんだかよく分かりませんが、HTTP/3を使用したすごい転送規格です。
双方向ですし、multiplexed-transport?かっこいいですね。
きっとブラウザOSが更に進化していくとか、ブラウザ上でゲームがネイティブアプリかのように動作するだとか、もうブラウザの意味が変わる時代が来るのかもしれません。
内容自体は難解かつ複雑ですが、今回はサンプルを触るだけですので何も考えずにやってみようと思います。
サーバー準備。
「WebTransportの実験」によると、現時点では、WebTransportはまだ公開されていません。
「試してみましょう」の項目にもありますが、HTTP/3サーバーをローカルで準備して起動する必要があるとのこと。
JavaScriptクライアントは、以下のURLに用意してくれています。
https://googlechrome.github.io/samples/webtransport/client.html
HTTP/3サーバーとは?
となったところで、GoogleChrome/samplesのgithubのスクリプトの中にコメントで、
An example WebTransport over HTTP/3 server based on the aioquic library. とありました。
aioquic。
aioquicを検索してみるとすぐ出てきたので、githubからcloneしてきます。
https://github.com/aiortc/aioquic/
導入は README の通りに進めます。
親切なことに、ブラウザの起動方法やオプションの説明、test/ ディレクトリの下に .pem ファイルまで用意されています。(独自証明書の場合のハッシュの生成コマンドもあります。)
Chromeもこれぐらいやって欲しい
また、aioquic/exapmplesにHTTP/3のテスト用サンプルが置いてあります。
試してみたところ、サーバー起動とHTTP/3のサンプルスクリプトは動作したのですが、クライアントからWebTransportの接続が上手くいきませんでした。深追いはしてませんが、バージョンアップで何か変わったのかもしれません。
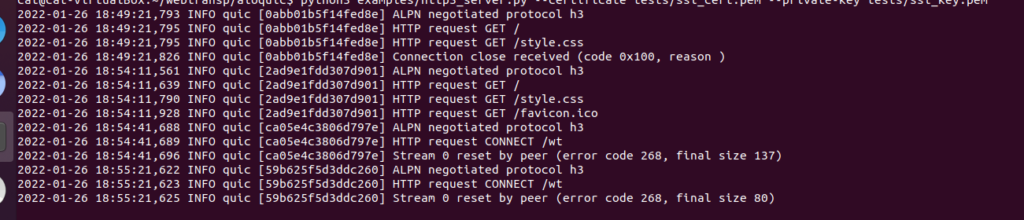
ということで、元のGoogleChrome/samplesに戻ります。
Chromiumからアクセス。
cloneしてきたGoogleChome/samplesからサーバー用スクリプトを起動します。
mv samples/webtransport/webtransport_server.py aioquic/
python3 webtransport_server.py tests/ssl_cert.pem tests/ssl_key.pem aioquicの説明の通り、Chromiumをコマンドから起動します。
chromium --enable-experimental-web-platform-features --ignore-certificate-errors-spki-list=BSQJ0jkQ7wwhR7KvPZ+DSNk2XTZ/ MS6xCbo9qu++VdQ= --origin-to-force-quic-on=localhost:4433 https://localhost:4433/ 上の方で紹介したJavaScriptクライアントを開きます。
https://googlechrome.github.io/samples/webtransport/client.html
画面にある「Connect」を押し、以下のように表示されると接続成功です。
Initiating connection...
Connection ready.
Datagram writer ready.
Datagram reader ready.お疲れさまでした。