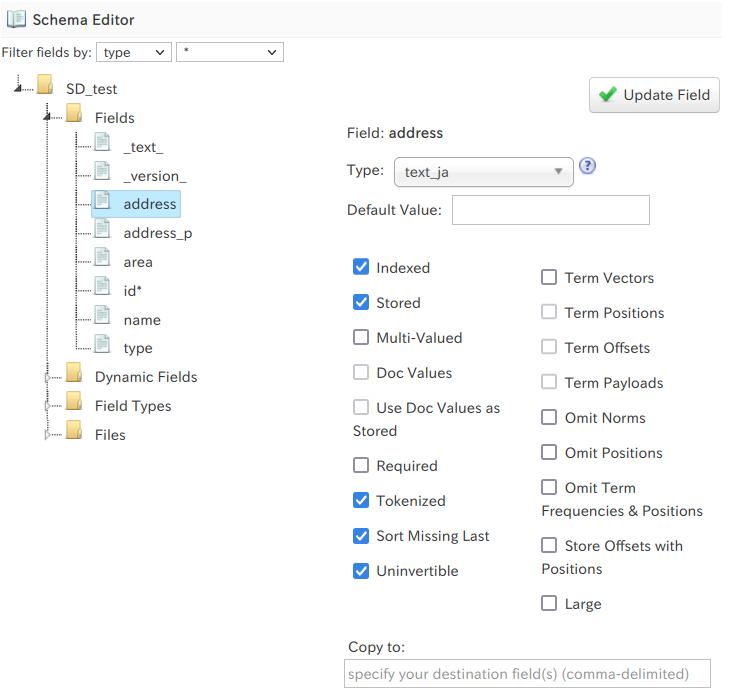
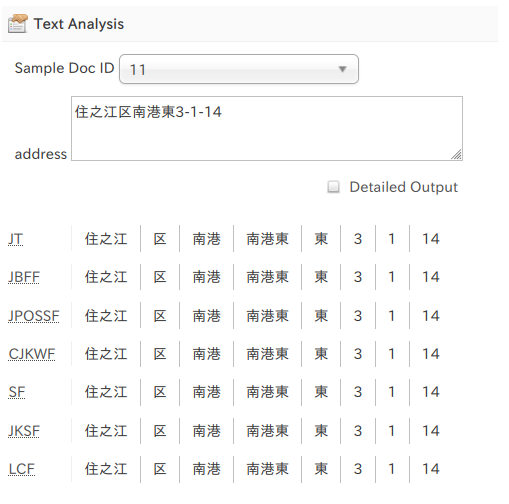
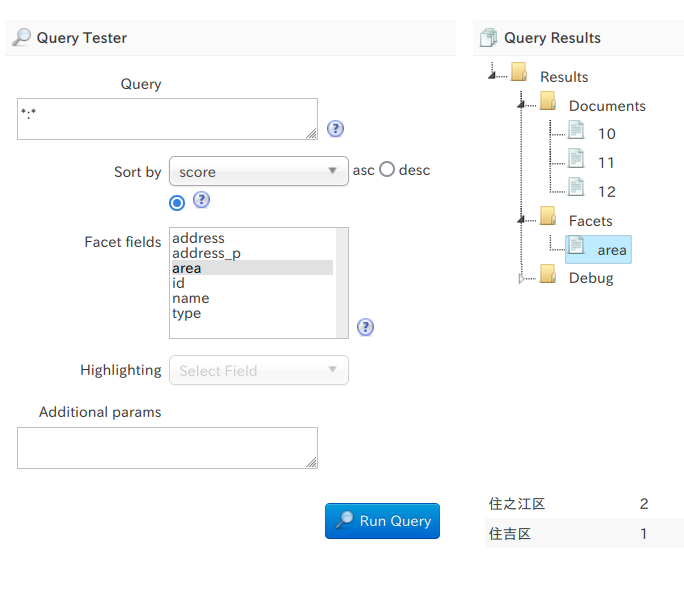
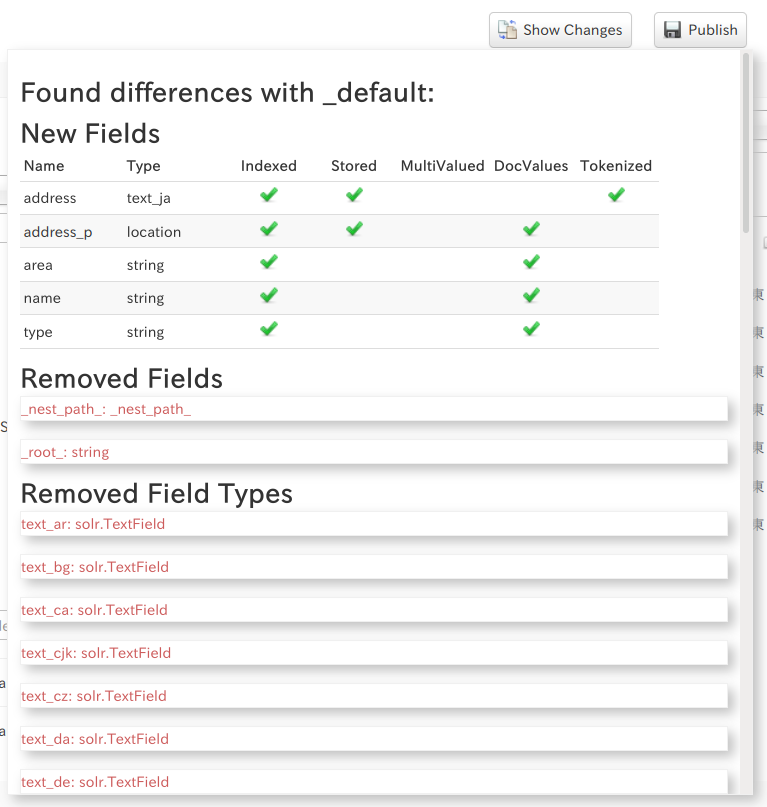
SolrCloudにおけるレプリカの種類
ドキュメント数の非常に多いコレクションを扱う場合、複数のシャードを作ってデータを分けることができます。ドキュメントはそれぞれ複数のシャードのどれか1箇所にだけ属します。
シャードは1個以上のレプリカから構成されます。同じシャードに属するレプリカの内容はすべて同じです。シャードのうちどれか一つがリーダーとして選ばれます。
インデックス対象のドキュメントがSolrに送られてきたとき、まずそのドキュメントがどのシャードに属するべきかが決定され、そのシャードのリーダーにドキュメントが送られます。そして同じシャードに属する他のレプリカすべてにリーダーからドキュメントが転送されます。
レプリカにはいくつか種類があります。
NRT(= NearRealTime)
- デフォルトの設定。トランザクションログを保持しつつ自身のローカルのインデックスの更新も行う。
- リーダー選出の候補となる。
TLOG
- トランザクションログの維持はするが、自身ではローカルのインデックス更新は行わない。
- このタイプのレプリカはコミットを実行する必要が無いのでインデックスの速度向上が見込める。
- このタイプのレプリカでインデックスを更新するには、リーダーからインデックスをレプリケートする。
- リーダー選出の候補となる。
- もしもリーダーに選出された場合には、NRTレプリカと同様に動作する。
PULL
- トランザクションログの維持もローカルのインデックス更新もせず、リーダーのインデックスのレプリケーションのみを行う。
- リーダー選出の候補にはならない。
レプリカのうちどれかはリーダーにならなければならないので、シャードのレプリカをすべてPULLだけで構成することはできません。
Solrリファレンスでお薦めされているレプリカタイプの組み合わせは以下の通りです。
すべてNRT
更新のリアルタイム性が必要でありインデックス更新のスループットがそれほど大きくない場合、この組み合わせにする。
特にSoft Commitが必要な場合はNRTしか選択肢が無い。
すべてTLOG
インデックス更新のリアルタイム性が必要でなくシャード内のレプリカが非常に多い場合、すべてのレプリカで更新リクエストを扱えるようにしておきたいと考えるならば、この組み合わせにする。
TLOGとPULLの組み合わせ
インデックス更新のリアルタイム性が必要でなくシャード内のレプリカが非常に多い場合、多少古い検索結果を許容しつつ検索クエリへの応答能力拡大をするにはこの組み合わせにする。