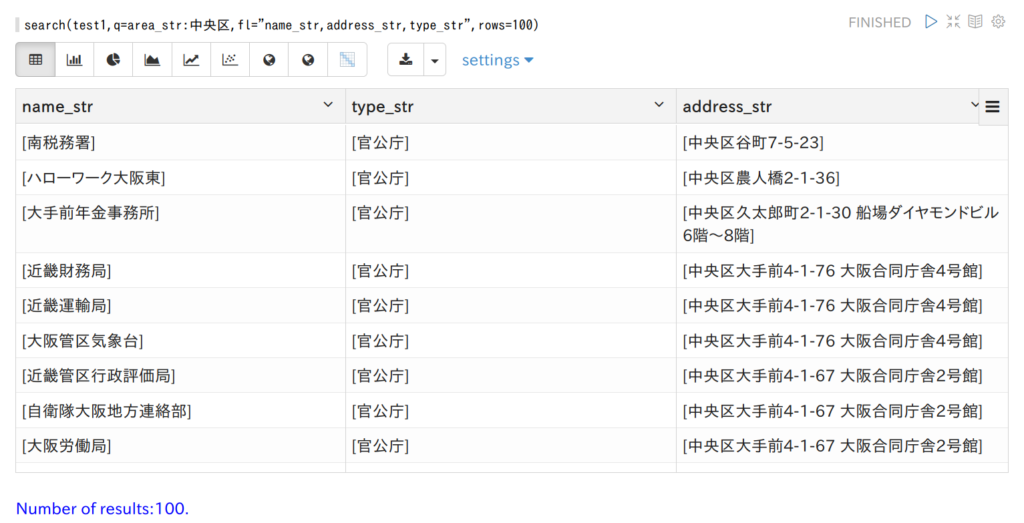
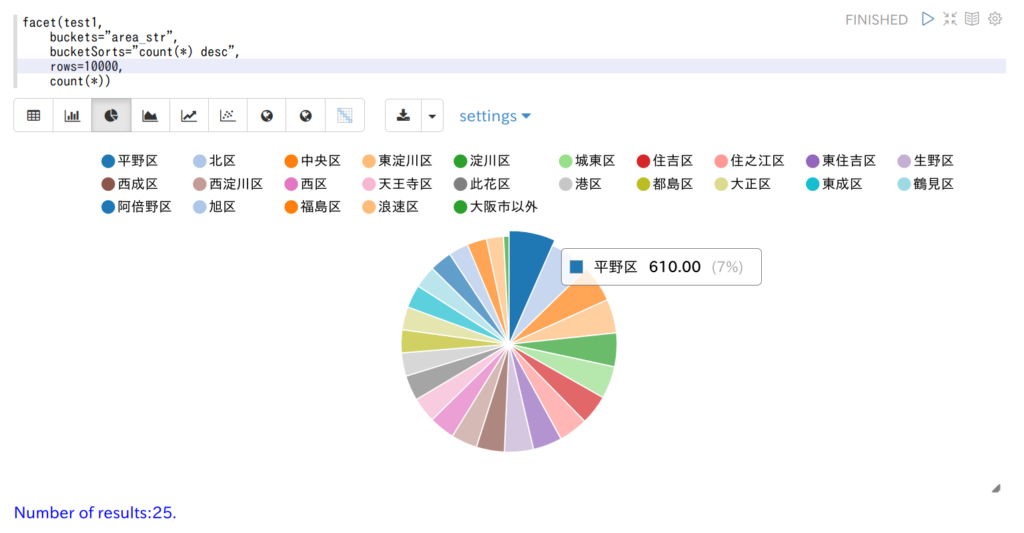
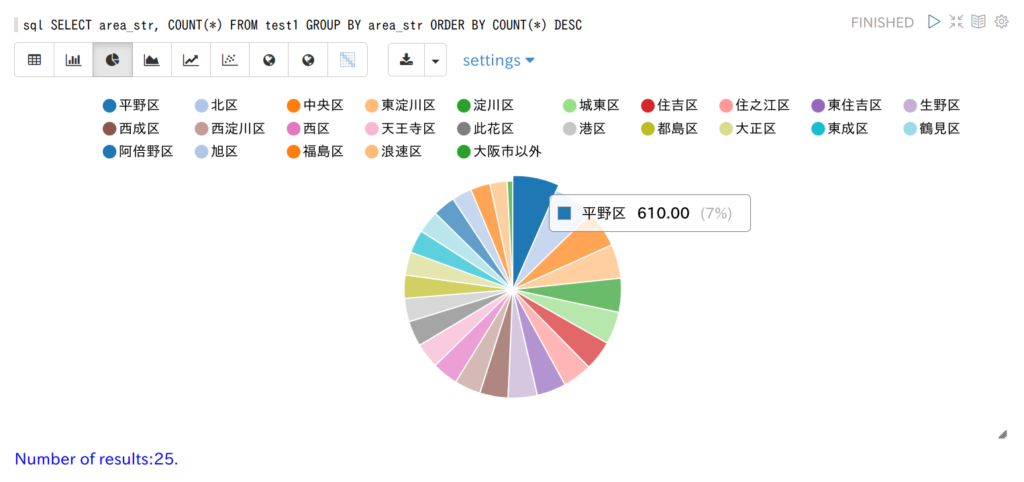
しっかり準備しよう

卯年なので『飛躍』などと書きたいところですが、今年はまだまだ「準備」の時期と位置づけて取り組んでいきたいと考えています。
今期スプラウトは第9期となります。
10期に向けて、8期が始まった頃くらいから新しい事業体制を模索してきました。
徐々に輪郭が固まってきたので今期も継続してしっかりと「準備」を進めていきたいと考えます。
メンバーのみんな、お世話になっている方々、本当に感謝しかありません。
ありがとうございます。
「準備」というコトバが自分の中であらためて大事なことと気づいたきっかけは、中田英寿さんがサッカー日本代表の時期にインタビューで「準備をしっかりする」ということをよく答えられていたことにあります。
結果のためには十分な準備をすることが大事。
当たり前かもしれませんが、とても難しいことだと思います。
スプラウトは、本年もひとつひとつしっかりと準備し、「ITサービスで日常を少し豊かにする」というビジョン実現に邁進してまいります!
<追記>
余談ですが、中田英寿さんは尊敬する方のひとりであり、僕と同じ誕生日で勝手にご縁を感じております。
1月22日はカレーの日。※ 僕の好きな食べものはカレーです。