「RubyWorld Conference 2021」に協賛させていただきます

「RubyWorld Conference 2021」に、Goldスポンサーとして協賛させていただきます。
<期間>
2021年12月16日(木)
<開催形式>
オンライン
<主催>
RubyWorld Conference開催実行委員会
https://2021.rubyworld-conf.org/ja/
「RubyWorld Conference 2021」に、Goldスポンサーとして協賛させていただきます。
<期間>
2021年12月16日(木)
<開催形式>
オンライン
<主催>
RubyWorld Conference開催実行委員会
https://2021.rubyworld-conf.org/ja/
ハロウィンでの一番お楽しみは、「ハロウィン ケーキ」で検索することです。
(この記事を書いているのはハロウィン前)
ケーキだけではなく、菓子類も奇抜な見た目をしていてとても面白いです。
というわけで、今年のハロウィン。

エビフライコロッケのハンバーガー作りました。
レンジで温めたポテトもあったのでバーガーセットですね。
ハロウィンにバーガー?と思うかもしれませんが、特に意味はありません。
近くのマ○クが改装中で食べられなかったことがショックで発作が起きてしまいました。
お菓子は、洋菓子のお店で買ったマドレーヌやクッキーがあったのですが、
食べてしまったので入れ物だったカボチャとゴーストのポーチを撮りました。
年間通してみても、
蜘蛛や蝙蝠、血や目玉に寛容なイベントはハロウィンくらいではないでしょうか。
アレンジや独自の工夫により、
合体事故を起こしてしまったものが生まれることもありますが、
それもハロウィンの楽しみの一つです。
とはいえ、今年は閉店してしまったお店も少し増えたように感じます。
今年もハロウィンの変わったお菓子が食べられることに感謝👏
Twitterで、Realistic Paint Studioというアプリが紹介されているのを見かけたので、有料のアプリでしたが購入してiPadにダウンロードしてみました。
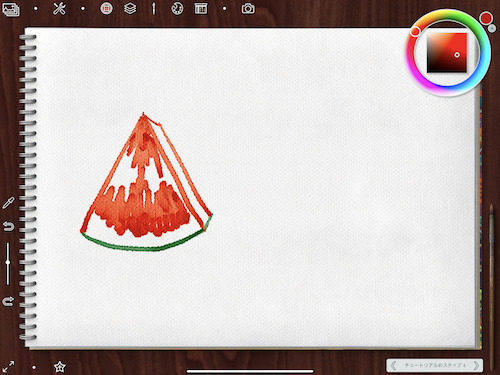
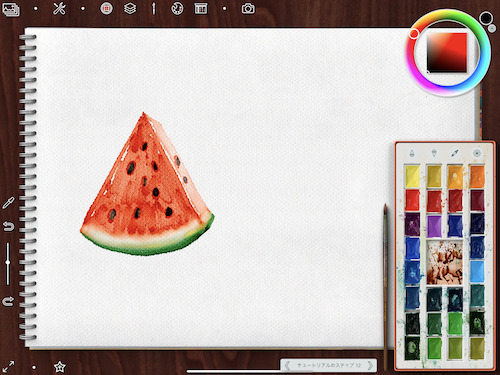
これはチュートリアルの一部なのですが、なんとツール自体の使い方のチュートリアルではなく、水彩画の描き方をチュートリアルで教えてくれるのです。
実際の水彩画も、大体このような手順で描いていたと記憶しています。
リアルすぎる…

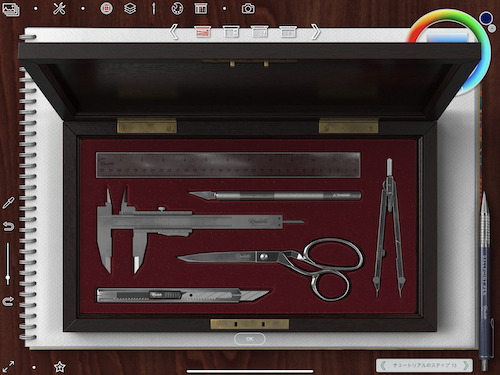
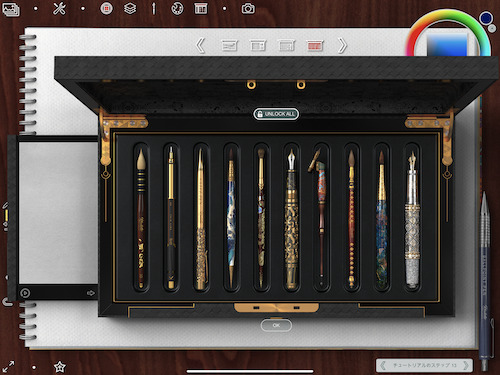
これはツール選択画面です。
私は文房具や画材の類が大好きなので、これだけでもかなりテンションが上がります…!
アナログ画材っぽい書き心地のソフトなどはこれまでも色々とありましたが、ここまで画材自体のビジュアルが推されているお絵描きツールは初めて見ました。
仕事などで絵を描く時はシンプルで使いやすいUIのアプリの方がいいですが、ゆっくり時間をかけて好きなように描きたい時にはこのUIは筆や絵具を選ぶ楽しさも味わえて良いかもしれません。
時々思い出したように襲い来る「アナログの画材触りたい!!!」の欲求は、このアプリでもだいぶ満たすことができそうです。

水彩画の他に、素描モードと油彩モードがあります。
値段は1,480円と、絵に全く興味のない人が試しに入れてみるアプリとしては少し高いかも…
ですが、画材やアナログ絵画が好きな人や、アナログ画材を試してみたい人はかなり満足できると思います!
(アナログ画材を実際に買うと1,480円では全く済まないので…)
今のところ水彩モードしかまだ触れていないので、ゆっくり他二つのモードも試してみたいと思います!
以前書いた「Solrで入れ子構造の文書をインデックスする」という記事で対象としていたのはSolr 7.5でしたが、現時点での最新版のSolr 8.8ではいろいろと変わった部分があるので改めて採り上げてみます。
Solr 7.5 の頃と変わったのは以下の点です。
Nested Documents を扱うためのスキーマ設定は以下の通りです。
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
インデックス作成時にSolrが自動的に作成するフィールドです。入れ子になったドキュメントはルートドキュメント(一番の先祖にあたるドキュメント)のidフィールドの値を _root_ フィールドの値として持ちます。
<fieldType name="_nest_path_" class="solr.NestPathField" /> <field name="_nest_path_" type="_nest_path_" />
入れ子構造のルートドキュメント以外のドキュメントにSolrが自動的に付与するフィールドです。このフィールドは検索結果を取得するときに ChildDocTransformer で子ドキュメント以下の階層構造を扱うのに使われます。もしこのフィールドが無い場合はすべての子孫がフラットなリストとして扱われます。
_nest_path_ フィールドを使わない場合は、それぞれの階層を区別するための自前のフィールドを定義することが推奨されます。(手間が掛かるだけなので、素直に _nest_path_ フィールドを使った方が良さそうです)
<field name="_nest_parent_" type="string" indexed="true" stored="true" />
ルートドキュメント以外のドキュメントにSolrが自動的に付与するフィールドです。親ドキュメントのidフィールドの値を持ちます。
以下のようなプレイリスト情報を Solr に与えます。
(_default の configset でコレクションを作っていればスキーマレスでインデックス作成できます)
[{
"id":"list_1",
"title_t":"list1",
"songs":[
{
"id":"l1!song1",
"title_t":"title1",
"artist_t":"artist1",
"trackNum_i":1
},
{
"id":"l1!song2",
"title_t":"title2",
"artist_t":"artist2",
"trackNum_i":2
}
]
},
{
"id":"list_2",
"title_t":"list2",
"songs":[
{
"id":"l2!song1",
"title_t":"title3",
"artist_t":"artist3",
"trackNum_i":1
},
{
"id":"l2!song2",
"title_t":"title1",
"artist_t":"artist1",
"trackNum_i":2
}
]
},
{
"id":"list_3",
"title_t":"list3",
"sublist":[
{
"id":"l3!sublist1",
"title_t":"sublist1",
"songs":[
{
"id":"l3!song1",
"title_t":"title4",
"artist_t":"artist4",
"trackNum_i":1
},
{
"id":"l3!song2",
"title_t":"title2",
"artist_t":"artist2",
"trackNum_i":2
}
]
},
{
"id":"l3!sublist2",
"title_t":"sublist2",
"songs":[
{
"id":"l3!song3",
"title_t":"title1",
"artist_t":"artist1",
"trackNum_i":1
},
{
"id":"l3!song4",
"title_t":"title3",
"artist_t":"artist3",
"trackNum_i":2
}
]
}
]
}]
ヒットしたプレイリストの子ドキュメントを取得するために ChildDocTransformer を利用します。
$ curl 'http://localhost:8983/solr/nestedDocuments/select' -d 'omitHeader=true' --data-urlencode 'q={!parent which="title_t:list1 -_nest_path_:*"}' -d 'fl=*,[child]'
{
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"list_1",
"title_t":"list1",
"_version_":1697935145902800896,
"songs":[
{
"id":"l1!song1",
"title_t":"title1",
"artist_t":"artist1",
"trackNum_i":1,
"_version_":1697935145902800896},
{
"id":"l1!song2",
"title_t":"title2",
"artist_t":"artist2",
"trackNum_i":2,
"_version_":1697935145902800896}]}]
}}
_nest_path_ フィールドでルート直下の songs の階層を指定しています。 {!parent} 内での -_nest_path_:* は「_nest_path_フィールドを持つもの以外」つまりルートドキュメントだけを対象とするという意味です。
$ curl -s 'http://localhost:8983/solr/nestedDocuments/select' -d 'omitHeader=true' --data-urlencode 'q={!parent which="*:* -_nest_path_:*"}(+_nest_path_:\/songs +title_t:title1)' -d 'fl=*,[child]'
{
"response":{"numFound":2,"start":0,"numFoundExact":true,"docs":[
{
"id":"list_1",
"title_t":"list1",
"_version_":1697935145902800896,
"songs":[
{
"id":"l1!song1",
"title_t":"title1",
"artist_t":"artist1",
"trackNum_i":1,
"_version_":1697935145902800896},
{
"id":"l1!song2",
"title_t":"title2",
"artist_t":"artist2",
"trackNum_i":2,
"_version_":1697935145902800896}]},
{
"id":"list_2",
"title_t":"list2",
"_version_":1697935145926918144,
"songs":[
{
"id":"l2!song1",
"title_t":"title3",
"artist_t":"artist3",
"trackNum_i":1,
"_version_":1697935145926918144},
{
"id":"l2!song2",
"title_t":"title1",
"artist_t":"artist1",
"trackNum_i":2,
"_version_":1697935145926918144}]}]
}}
_nest_path_ フィールドで sublist 階層の下の songs の階層を指定しています。
$ curl -s 'http://localhost:8983/solr/nestedDocuments/select' -d 'omitHeader=true' --data-urlencode 'q={!parent which="*:* -_nest_path_:*"}(+_nest_path_:\/sublist\/songs +title_t:title1)' -d 'fl=*,[child]'
{
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"list_3",
"title_t":"list3",
"_version_":1697935153103372288,
"sublist":[
{
"id":"l3!sublist1",
"title_t":"sublist1",
"_version_":1697935153103372288,
"songs":[
{
"id":"l3!song1",
"title_t":"title4",
"artist_t":"artist4",
"trackNum_i":1,
"_version_":1697935153103372288},
{
"id":"l3!song2",
"title_t":"title2",
"artist_t":"artist2",
"trackNum_i":2,
"_version_":1697935153103372288}]},
{
"id":"l3!sublist2",
"title_t":"sublist2",
"_version_":1697935153103372288,
"songs":[
{
"id":"l3!song3",
"title_t":"title1",
"artist_t":"artist1",
"trackNum_i":1,
"_version_":1697935153103372288},
{
"id":"l3!song4",
"title_t":"title3",
"artist_t":"artist3",
"trackNum_i":2,
"_version_":1697935153103372288}]}]}]
}}
先日、MDN Web Docs で調べものをしているときに、
たまたま面白そうなサンプルを見つけました。
今日は、それを使って遊んでみたいと思います。
その前に、MDN Web Docs について分からない人向けに簡単に説明すると、
Mozilla.org による、Web技術者向けのドキュメントが集まったウェブサイトです。
MDN Web Docs (以前は MDN — Mozilla Developer Network と呼ばれていました) は、ウェブ技術とウェブを支えるソフトウェア、 CSS、 HTML、 JavaScript などについて学ぶための進化し続ける学習プラットフォームです。
MDN Web Docs について – MDN プロジェクト | MDN (mozilla.org)
私の中で、辞書変わりに常に開いておきたいサイトランキング1位に輝いています。
人によっては、読んでるだけで楽しい! ワクワクする! という噂もあります。
今回取り上げるサンプルと、元になるコードは以下にあります。
KeyboardEvent.code – Web APIs | MDN (mozilla.org)
“Try it out” と書かれた文字の下に、
黒い正方形と、その中にオレンジの二等辺三角形が描画されています。
コードを見ると、
オレンジの二等辺三角形は spaceship という名前のようです。
黒い四角は world。
私がつけたわけではありません。
が、ここに世界と、宇宙船が誕生したわけです。
ここからコードを追加し、
スペースキーを押すとショットを撃てるようにしたいと思います。
一部抜粋ですが、こんな感じに。
const spaceship = document.getElementById("spaceship");
const shot = document.getElementById("shot");
const world = document.querySelector('.world');
let isFiring = false
function refresh() {
let x = position.x - (shipSize.width/2);
let y = position.y - (shipSize.height/2);
let transform = "translate(" + x + " " + y + ") rotate(" + angle + " 15 15)";
spaceship.setAttribute("transform", transform);
if (isFiring) {
let rad = angle * (Math.PI / 180);
shotPosition.x += (Math.sin(rad) * shotMoveRate);
shotPosition.y -= (Math.cos(rad) * shotMoveRate);
let sx = shotPosition.x + (shipSize.width / 2);
let sy = shotPosition.y + (shipSize.height / 2);
shot.setAttribute("transform", 'translate(' + sx + ' ' + sy +')');
if (isOutOfArea(sx, sy)) {
isFiring = false;
}
} else {
shotPosition.x = x;
shotPosition.y = y;
}
}
function isOutOfArea(x, y) {
return (x < -1 || x > world.clientWidth || y < -1 || y > world.clientHeight);
}
setInterval(() => {
refresh();
}, 33);
MDN のコードは、あくまでも KeyboardEvent のサンプルなので、
キーボードを押した際にしか処理が行われないようになっています。
これはこれで省エネなのですが、
この世界の神がキーボードを押している間しか時間が進みませんので、
いろいろと不都合です。
定期的に画面を描画し直すように変更しました。
次に、スペースキーで shot を発射するための処理を入れるのですが、
この宇宙船は、2次元平面上で回転します。
宇宙船の向きに合わせて前方に発射しましょう。
宇宙船と角度を合わせて、
座標を移動させるだけです。
無事、撃てるようになったら、
世界の領域を越えたショットを消すようにします。
宇宙の外に迷惑をかけてはいけません。
ここまでの動作サンプルを置いておきます。
下の枠内をクリックすると読み込みます。
推奨環境は Google Chrome、MS Edge です。
気付いた人もいらっしゃるかもしれませんが、
angle の値を使いまわしているため、
ショットを撃ったあとに回転するとショットがカーブします。
これはこれで面白いかと思い放置しています。
自機が動いてショットを撃つ。
これだけでも、
なんとなくゲームのような片鱗が見えてきたのではないでしょうか。
360度全方位の2Dシューティングゲーム (画面は3D) が
何年か前にありましたが、
ものすごく頑張ればそれに近いものが作れるかもしれません。
MDN にはいろいろな動作サンプルがあります。
あなたの求めるものが意外なところから見つかるかもしれません。