こんにちは、デザイナーのはなです。
最近小さい鳥を飼い始めました。かわいいです。
認知特性テストをやった
https://overpass.dokkoisho.com/cognitive/
こちらの本田35式認知テストというものが少し前に流行っていたので、やってみました。
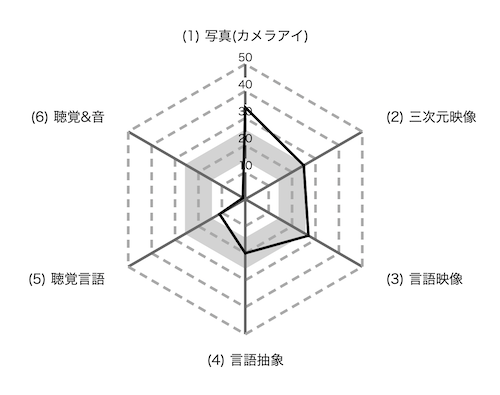
写真(カメラアイ)タイプ 写真のように二次元で思考するタイプ
三次元映像タイプ 空間や時間軸を使って三次元で考えるタイプ
言語映像タイプ 文字や文章を映像化してから思考するタイプ
言語抽象タイプ 文字や文章を図式化してから思考するタイプ
聴覚言語タイプ 文字や文章を耳から入れる音として情報処理するタイプ
聴覚&音タイプ 音色や音階といった音楽的イメージを脳に入力するタイプ
カメラアイと聴覚&音の間が断崖絶壁みたいになっている…
聴覚に関する項目の点数が著しく低い、つまり音声での情報効率がもうむちゃくちゃ悪いということになります。
そう考えると、電話しながらTwitterを見ると、友達との会話の内容がわからなくなることもこれが原因だと言えます。
私の場合、情報入力(視覚)と情報入力(聴覚)を戦わせると、視覚からの情報が必ず勝ってしまうということです。
自分が聴覚情報の処理が苦手であるということは昔から正直若干自覚があったため、授業などで板書少なめで喋りまくる先生の授業では聞くのを途中で諦めて、要点の単語のみメモし、あとから教科書や資料集やネットなどで調べて自分の目で見たものを情報として補完していたこともありました。
また、私の学生時代のノートは、落書きもイラスト図解もめちゃくちゃ多いため、絵だらけでした。
それはあんまり今も変わってないですね。(ミーティング中のメモが絵だらけな人)
他人の認知特性をふわっと推し量る
他の人になにかの情報を渡したり、好きなものをおすすめしたりするときに、相手の認知特性がなんとなくわかっていると何かと便利です。
例えばですが、私の友人の一人に、一緒に映画を見に行ったあと「あのシーンよかったよね〜」など感想を話すとき、必ず「あのセリフの表現が…」と、文章としての表現について話す人がいます。
私が映画の感想を話すときは、印象的なシーンの構図や、光の当たり方などについて思い返すことが多いので、おそらく私と認知特性が違うんだろうな、と解るわけです。
なので理解してほしい事があるときは、文章で説明してくれているサイトを探してきたり、少し長文になったとしても文章で説明するように心がけています。
何かの記憶について話したり、何かを説明してもらったりしたときに、その人の得意な情報処理方法が滲んで出ていると感じることが多いです。
もちろん全然わからないときも同じぐらい多いので、その時は相手の顔色を見つつ、わかってなさそうなら説明方法を変え、色々試して結果的に同じことを3,4回繰り返して説明するようにしています。
また、なんとなく推し量った相手の認知特性は、絶対そうだ!ではなく、あくまでもなんとなく、もしかしたらそうかもな〜ぐらいの認識でいることが一番大切です。
まとめ
優位特性についてテストしてみて思ったことは、自分のパラメータで突出している部分や陥没している部分があるように、他人にだってそういう部分があるんだろうなということです。
私の聴覚&音が1点であるように、視覚が1点の人だってもちろんいるわけです。
私が、音声だけでばーっとたくさんの情報を渡されたときにほとんど理解できなくて涙目になることがあるように、私がわかりやすいからと言って絵や図だけで情報を渡してしまうと、理解できなくて涙目になる人がかならずどこかに存在しているわけです。
自分がわかりやすいからといって、他の人もわかりやすいとは限らないということは、デザイナーという職業だからこそ特に気をつけなければいけないことだな、と痛感しました。
また、聴覚情報しか用意されていない場合でも、少しでも多く情報を理解できるように、例えば目を閉じて視覚情報をシャットダウンしたり、グラフィックレコードのようなことをしてみたり、ゆっくり話してもらうようにお願いしてみたり…など、工夫する必要があるなと思いました。
https://blog.splout.co.jp/33/
優位特性についてはこちらの記事でも触れられています。