WordPressでお知らせや商品一覧などデフォルトで用意されている投稿とは別に、独立したコンテンツを投稿したい場合ってありますよね。
そんなときは、カスタム投稿タイプを使って投稿ページを増やしましょう!
①管理画面にカスタム投稿の追加
「functions.php」に下記のコードを追加します。
add_action( 'init', 'add_post_type' );
function add_post_type() {
// 「ニュース」のカスタム投稿タイプ
register_post_type(
'news', /* 投稿タイプ名 */
array(
'labels' => array( // 投稿タイプの名前を定義
'name' => 'ニュース', // 管理画面などの表示名
'singular_name' => 'ニュース', // 管理画面などの表示名(単数形)
'add_new_item' => '新規追加', // 新規追加画面の表示名
'edit_item' => '編集', // 編集画面の表示名
),
'public' => true, // trueで管理画面等に表示
'hierarchical' => true, // trueで階層型
'has_archive' => true, // trueでアーカイブページ(一覧表示)を持つ
'supports' => array( // カスタム投稿ページに表示される項目
'title', // タイトル
'editor', // 本文のエディタ
'author', // 作成者
'thumbnail', // アイキャッチ画像
'excerpt', // 抜粋
'trackbacks', // トラックバック送信
'custom-fields', // カスタムフィールド
'revisions', // リビジョン
'comments', // ディスカッション
'page-attributes', // 属性(親・順序)
),
'menu_position' => 5, // 左メニュー「投稿」の下に表示
'rewrite' => array('with_front' => false), // パーマリンクの編集(newsの前の階層URLを消して表示)
)
);
}
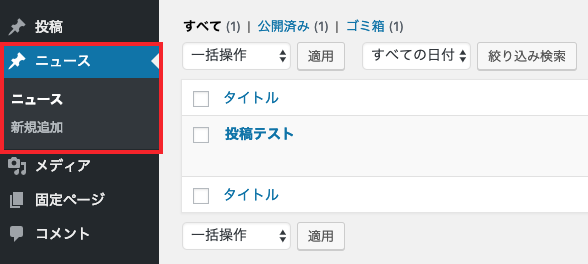
「functions.php」にコードを追加すると左メニューに「ニュース」が追加されます。
※ 不要なフォームがある場合は、「supports」の中の不要な値を削除してください。
※ 表示位置をもっと下にしたい場合は、menu_positionの値を増やしてください。
(例えばメディアの下に持っていきたい場合はmenu_positionの値を10にします。)
②カスタム投稿タイプの表示方法テンプレートの用意
次に記事表示用のテンプレート「single-news.php」を作成します。
ファイル名single-news.phpの「news」の部分は、function.phpに追記した「投稿タイプ名」と同じにします。
(single-news.phpがない場合はsingle.phpを使って表示されます。)
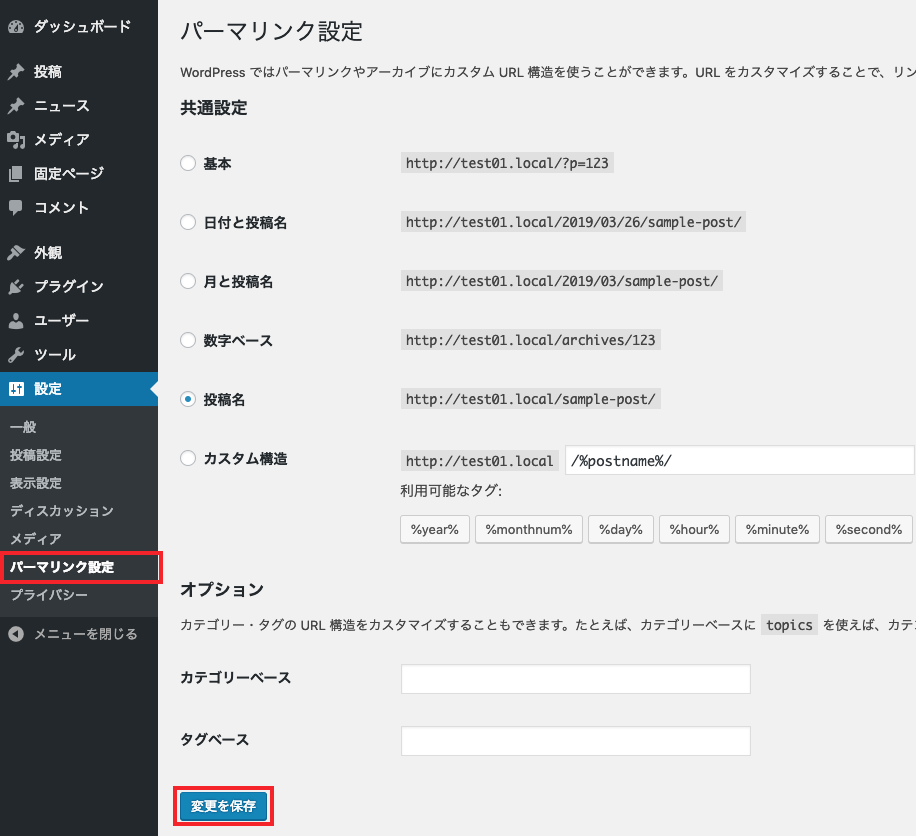
③パーマリンクの保存
「設定>パーマリンク設定」で内容を変更せずに、「保存」ボタンをクリックします。
(パーマリンク設定で保存をしないとエラーページが表示されます。)
「ニュース」で投稿した記事のURLにアクセスすると投稿した内容が表示されていると思います。
やってみると意外と簡単にカスタム投稿タイプが追加出来たのではないでしょうか?
こういう所から少しずつWordPressと親しくなれたらと思います。