SolrCloud 環境におけるスキーマの読み込みと保存について
はじめに
Solr 5.4.1 以降においては、スキーマは schema.xml を使うファイルベースの管理ではなく Schema API を使う管理が推奨されています。
Schema API を利用して設定された内容は managed-schema というファイルに書き込まれますが、このファイルを直接編集しないようにと公式ドキュメントには書かれています。
とはいえ、インデックスの初期設定時にはファイルで設定を与えられた方が便利です。
ManagedIndexSchemaFactory が使われる設定においては、 schema.xml が存在すれば自動的に schema.xml の内容を読み込んで schema.xml.bak にリネームしてから managed-schema ファイルが作られることになっています。
それ以降のスキーマ変更は Schema API を利用する訳です。
SolrCloud 環境においても実際に上記のような動作をするのかどうか、簡単な検証をしてみました。
準備
configsets の準備
_default の configsets をコピーして使います。
$ cd server/solr/configsets $ cp -r _default/ schema_convert $ rm schema_convert/conf/managed-schema $ vi schema_convert/conf/schema.xml $ cat schema_convert/conf/schema.xml
maganed-schema を削除して、_default/solrconfig.xml との組み合わせでエラーにならない最小限の schema.xml を作成。
<schema name="default-config" version="1.6">
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="key" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="val" type="pint" indexed="true" stored="true" required="true" multiValued="false" />
<uniqueKey>id</uniqueKey>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<fieldType name="pint" class="solr.IntPointField" docValues="true"/>
<fieldType name="plong" class="solr.LongPointField" docValues="true"/>
<fieldType name="booleans" class="solr.BoolField" sortMissingLast="true" multiValued="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<fieldType name="pdates" class="solr.DatePointField" docValues="true" multiValued="true"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
</schema>configsets アップロード
$ ../../scripts/cloud-scripts/zkcli.sh -zkhost localhost:9983 -cmd upconfig -confdir schema_convert/conf -confname schema_convert

検証
コレクション作成
$ curl 'http://localhost:8983/solr/admin/collections?action=CREATE&name=schema_convert&numShards=1&replicationFactor=1&collection.configName=schema_convert&wt=xml'
コレクション作成時に schema.xml が読み込まれたはずです。確認してみましょう。
zookeeper データツリー確認
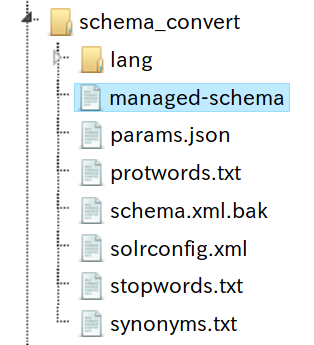
schema.xml が schema.xml.bak に変更されて managed-schema が作られたことが分かります。
Schema API による変更が managed-schema に反映されるか
変更前
$ curl -s http://localhost:8983/solr/schema_convert/schema/fields |grep name
"name":"_version_",
"name":"id",
"name":"key",
"name":"val",
Solr の管理画面で確認した managed-schema の内容(抜粋)

変更
curl -X POST -H 'Content-type:application/json' --data-binary '{
"add-field":{
"name":"label",
"type":"string",
"indexed":true,
"stored":true }
}' http://localhost:8983/solr/schema_convert/schema
“label” というフィールドを追加しました。
変更後
$ curl -s http://localhost:8983/solr/schema_convert/schema/fields |grep name
"name":"_version_",
"name":"id",
"name":"key",
"name":"label",
"name":"val",
Solr の管理画面で確認した managed-schema の内容(抜粋)

確かに変更内容が managed-schema に反映されました。
まとめ
通常の Solr core の環境では Schema API による設定変更は managed-schema の実ファイルに保存されます。
一方、SolrCloud の環境では各種設定ファイルは zookeeper 上にあるものを各ノードで共有する形になっています。schema.xml の読み込みや Schema API による変更の保存などは zookeeper のファイルツリー上で実ファイルと全く同じ内容が実行されることを確認できました。