こんにちは。開発担当のマットです。
私の初めての仕事は15歳の時でした。父の会社で、紙資料(パンフレットなど)を折りたたむ役でした。毎日8時間、紙を印刷して折りたたんで折りたたんで、フォルダーに綴じてをやっていました。つまらない仕事で時給はたったの 500 円でした。その後、日本に移住して保育園で働きながら日本語を必死に勉強して、翻訳や通訳の仕事もやりました。
そして、途中で私はプログラミングに憧れました。ソフトウェアの翻訳の仕事をしていたら自分でもソフトウェアを作りたいな!という気持ちになりました。ただ、その翻訳の仕事で多くの言葉に初めて出会いました。日本語でも英語でもないような言葉・・・英和辞典で調べても、どうしても理解できないプログラミング用語。
この記事でその用語をできるだけ簡潔でわかりやすく説明したいと思います。プログラミングは幅広い分野なので主にウェブアプリケーションを中心に説明しますが、ご興味があればぜひお読みください!
 とても短い辞典ですが・・・
とても短い辞典ですが・・・
API
Application Programming Interface
アプリケーション通しの通話窓口ですね。
例えば、Youtube に動画をアップすると自動的にTwitterに投稿する、という設定があるとしましょう。それを成し遂げるにはYoutubeはTwitter のサイトを開いてテキストボックスにメッセージを入力し「ツイート」ボタンを押しているわけではありません。
実は Twitter が裏で API というウェブページ(みたいなもの)を用意しています。 Youtube は特定の情報を添えて(認証データ、送りたいツイートの内容)、そのページにアクセスするだけでTwitter がそれを処理してツイートを投稿してくれます。
つまり、Twitter の API は他のアプリケーション(YoutubeやFacebookや個人が作ったサイトやゲームでも) が Twitter に仕事をお願いできるところです。
ウェブサイトだけではなく、ソフトウェア・アプリケーションやハードウェアにも、APIが存在しています。
バックエンド・フロントエンド
ウェブ系のアプリケーションでよく聞く言葉ですが、バックエンドとは、ユーザーが見えない部分です。フロントエンドはユーザーが見える部分となります。
たとえば、ウェブページのレイアウトはユーザに見られる部分ので、そのサイトのフロントエンドです。逆に、ウェブページの内容が保存されているデータベースはバックエンドと言います。
クライアントサイド・サーバーサイド
フロントエンド・バックエンドには似ていますが、クライアントが「ユーザのブラウザ(Chrome、Safari等)」、サーバーが「サービス側のサーバー」と考えたら、わかりやすいです。
例えば、ウェブサイトに都道府県の一覧があるとします。都道府県の順番を並べてあげたいのですが、ウェブページを送る前に並び替えてあげるならその処理はサーバーで行うので「サーバーサイド」です。
もし、ウェブページを送る時に並び替えスクリプトもページの中に埋め込んで、並び替え処理はサーバーではなくユーザのブラウザでされる場合は「クライアントサイド」と言います。
Google の検索結果の順番はGoogle が決めるのでサーバーサイドとなります。
逆に、Wikipedia での一覧リストの順番は(だいたい)ボタンを押せば、ブラウザが並び替えをしてくれるのでクライアントサイドとなります。
キャッシュ
一度完了した処理の結果を一時的に覚えることです。
例えば、通販サイトの場合ユーザがページを見ると今セール中の商品一覧を出したいかもしれませんね。
でも、誰かがページをアクセスすると毎回毎回何がセール中であるかをわざわざデータベースに確認して処理をするより一度だけやってその結果をメモリーは一時間だけ覚えます。
こうすると、データベースへの負荷が軽くなりウェブサイトのスピードが速くなるのでユーザが快適に買い物ができます。
暗号化・復号化
とても賢い数学を使って、データをごちゃごちゃで読めない状態にして(暗号化)、また読める状態に戻す(復号化)ことです。
暗号化の数学処理で指定の数字を使いますので、その「鍵」がないと復号化できません。
ハッシュ
ハッシングとは暗号化のようです。
データをごちゃごちゃに読めない状態にできますが、暗号化と違ってそのごちゃごちゃのデータを復号化できません。
復号化できないので、あまり用途がないように思えますが、アプリケーションがパスワードを保存する時に使えます。
パスワードをデータベースに保存してしまうと万が一ハッキングされてしまった時に漏洩してしまうので、復号化できないのはそれを避けるためです。
逆に、パスワードをハッシュして、ごちゃごちゃの状態で保存します。
そして、ユーザさんがログインする時にそのログインで使ったパスワードをハッシュして照合する。
どちらのごちゃごちゃも一致していると同じパスワードを入力したと判断できます。
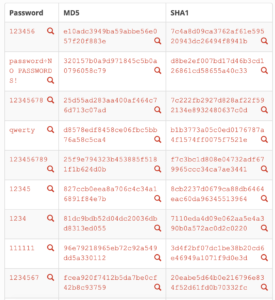 MD5 と SHA1 はハッシュ・アルゴリズムの種類です
MD5 と SHA1 はハッシュ・アルゴリズムの種類です
まとめ
他にもたくさんありますが、用語をちょっとでも紹介できたら嬉しいと思います。ここまで読まれているということはプログラミングに少しでも興味があると思いますので、私が以前に書いた「プログラミング言語とは」の記事もぜひ併せてお読みください!